
# The First Rust Class
# 开篇词
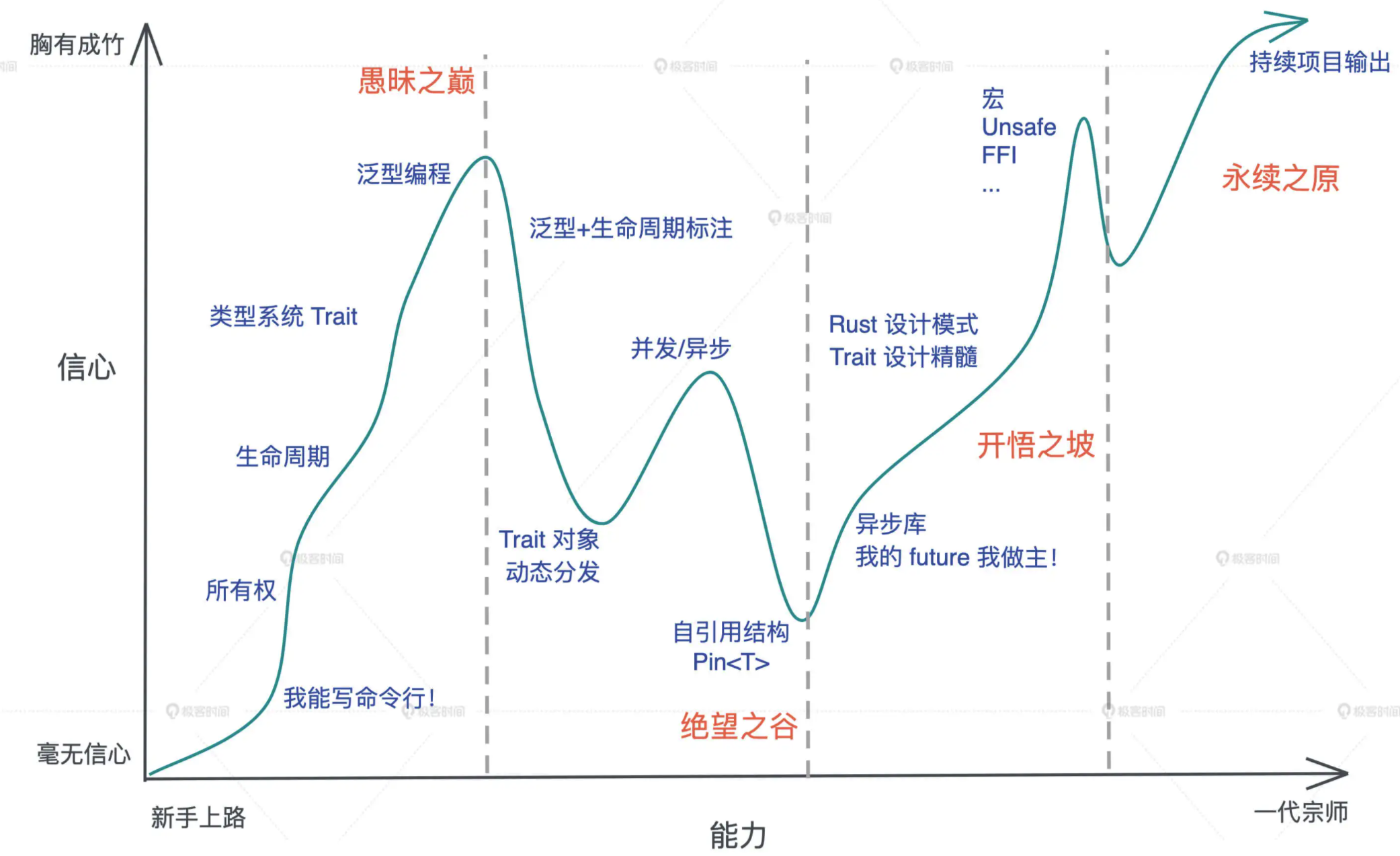
# 学习 Rust 的难点
- Rust 中最大的思维转换就是变量的所有权和生命周期
# 如何学好 Rust?
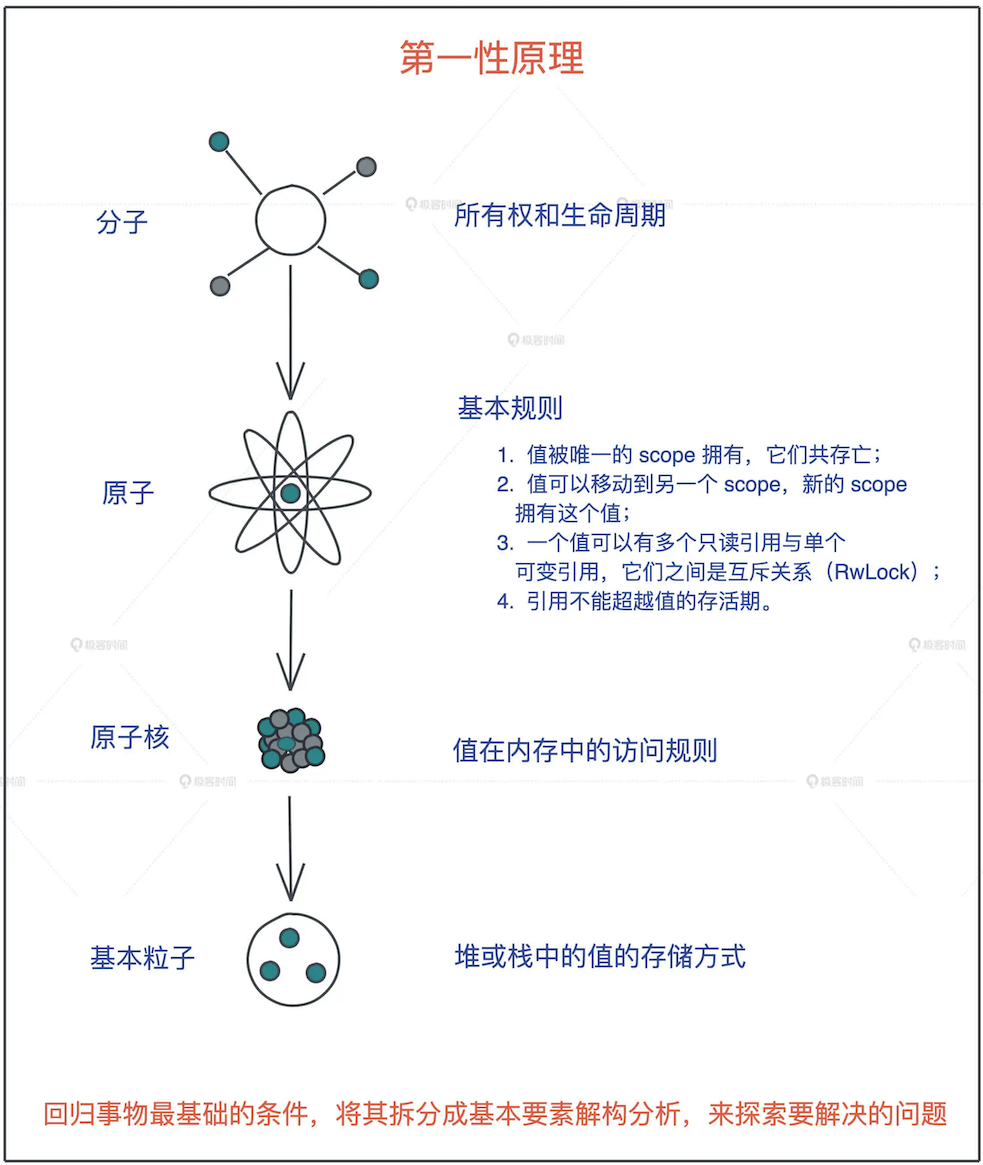
# 1. 精准学习
- 深挖一个个高大上的表层知识点,回归底层基础知识的本原,再使用类比、联想等方法,打通涉及的基础知识;然后从底层设计往表层实现,一层层构建知识体系
- 第一性原理:回归事物最基础的条件,将其拆分成基本要素解构分析,来探索要解决的问题。
# 2. 刻意练习
用精巧设计的例子,通过练习进一步巩固学到的知识,并且在这个过程中尝试发现学习过程中的不自知问题,让自己从“我不知道我不知道”走向“我知道我不知道”,最终能够在下一个循环中弥补知识的漏洞。
# 前置篇
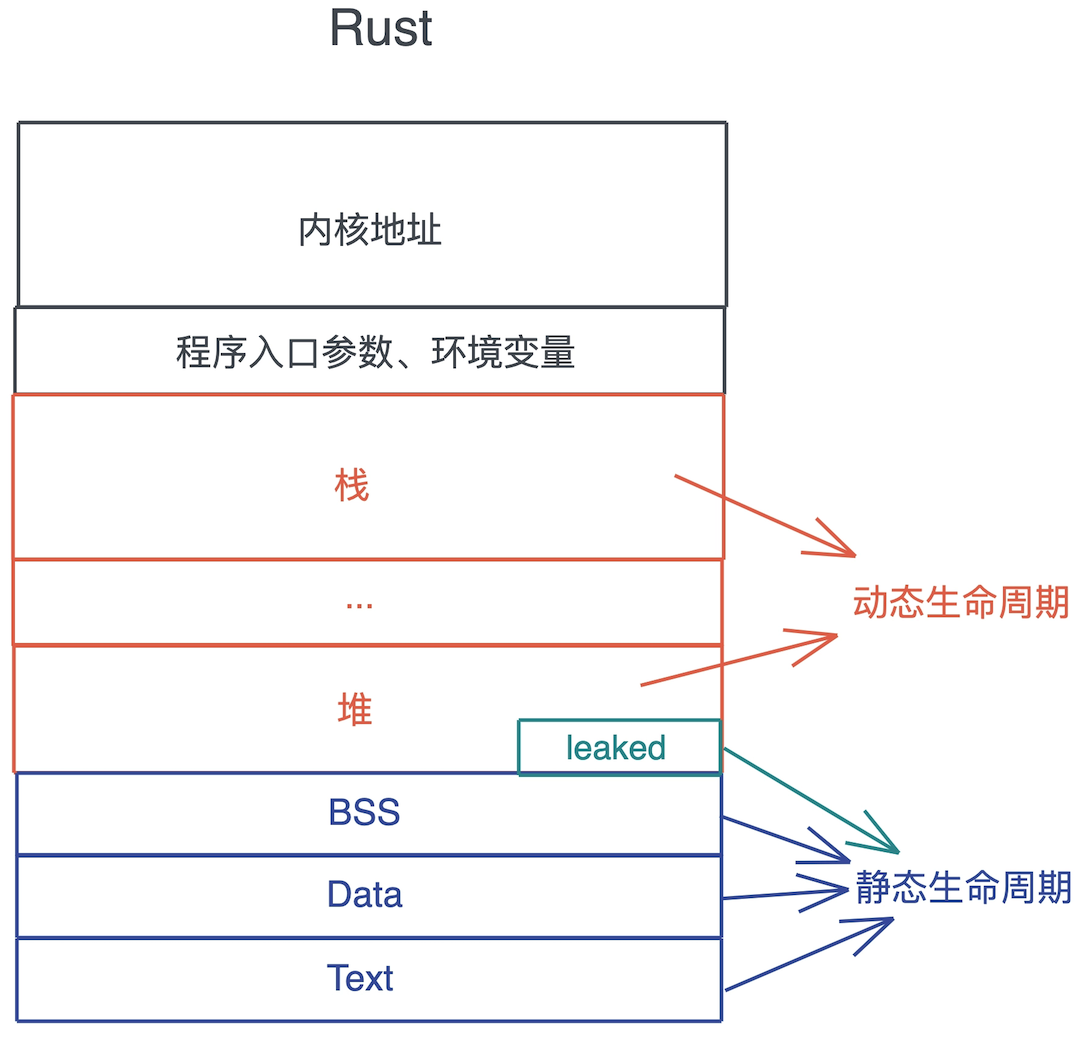
# 内存
每个线程分配一个 stack,每个进程分配一个 heap。stack 是线程独占,heap 是线程共用。 stack 大小是确定的,heap 大小是动态的。
栈上存放的数据是静态的,固定大小,静态生命周期;堆上存放的数据是动态的,不固定大小,动态生命周期。
# 栈
- 栈是自顶向下增长;
- 每当一个函数被调用时,一块连续的内存(帧 frame)就会在栈顶被分配出来;
- 一个新的帧会分配足够的空间存储寄存器的上下文;
- 在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。
- 栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。
- 所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。
- 对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
# 堆
- 堆可以存入大小未知或者动态伸缩(动态大小、动态生命周期)的数据类型。
- 堆上分配出来的每一块内存需要显式地释放,这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。
# 堆内存自动管理方式
- Tracing GC: tracing garbage collection; 追踪式垃圾回收
- ARC: Automatic Reference Counting; 自动引用计数
# 数据
# 值和类型
- 值是无法脱离具体的类型讨论的
# 类型
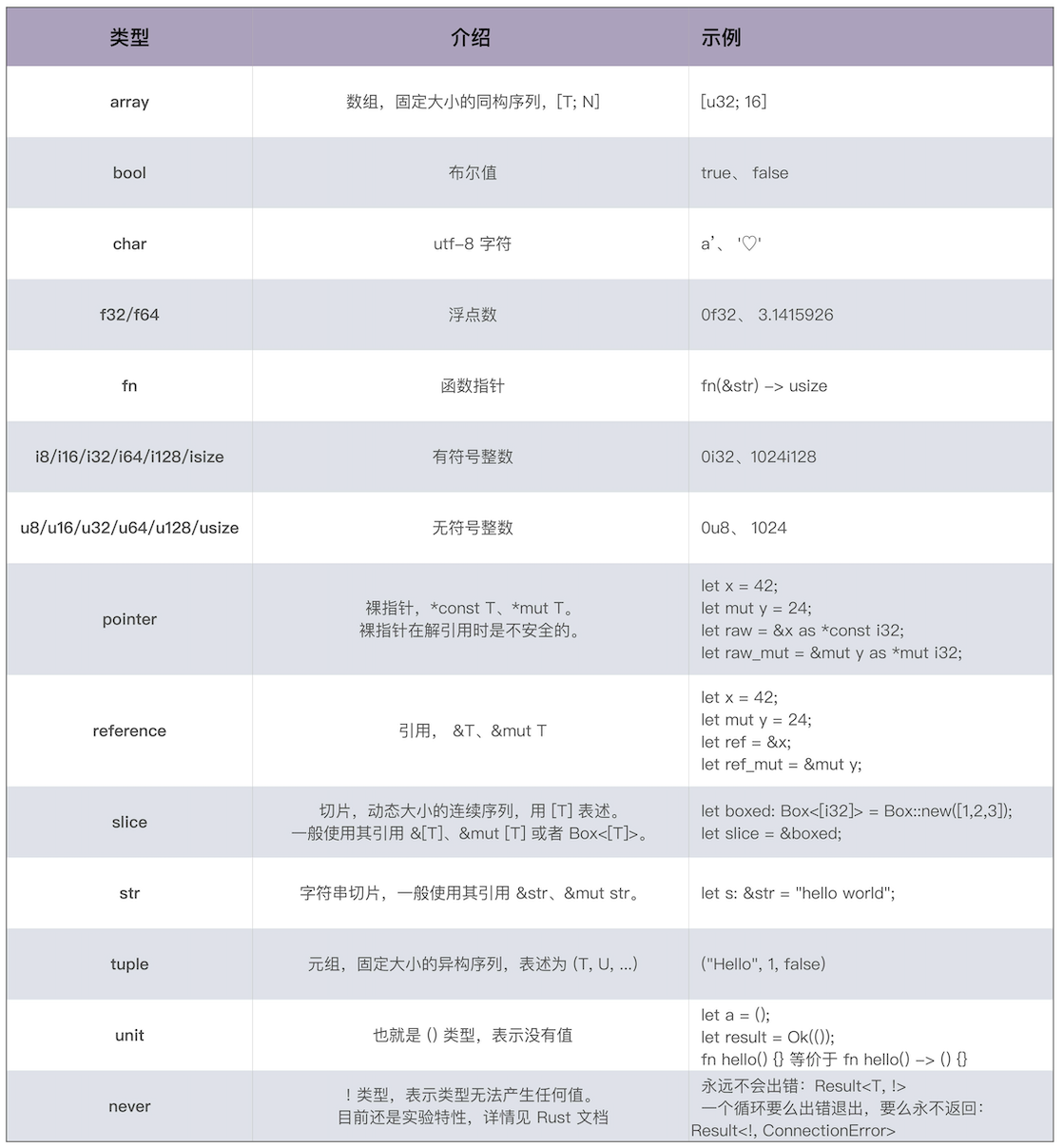
原生类型
- 字符、整数、浮点数、布尔值、数组(array)、元组(tuple)、指针、引用、函数、闭包
- 所有原生类型大小都是固定的,因此它们可以被分配到栈上。
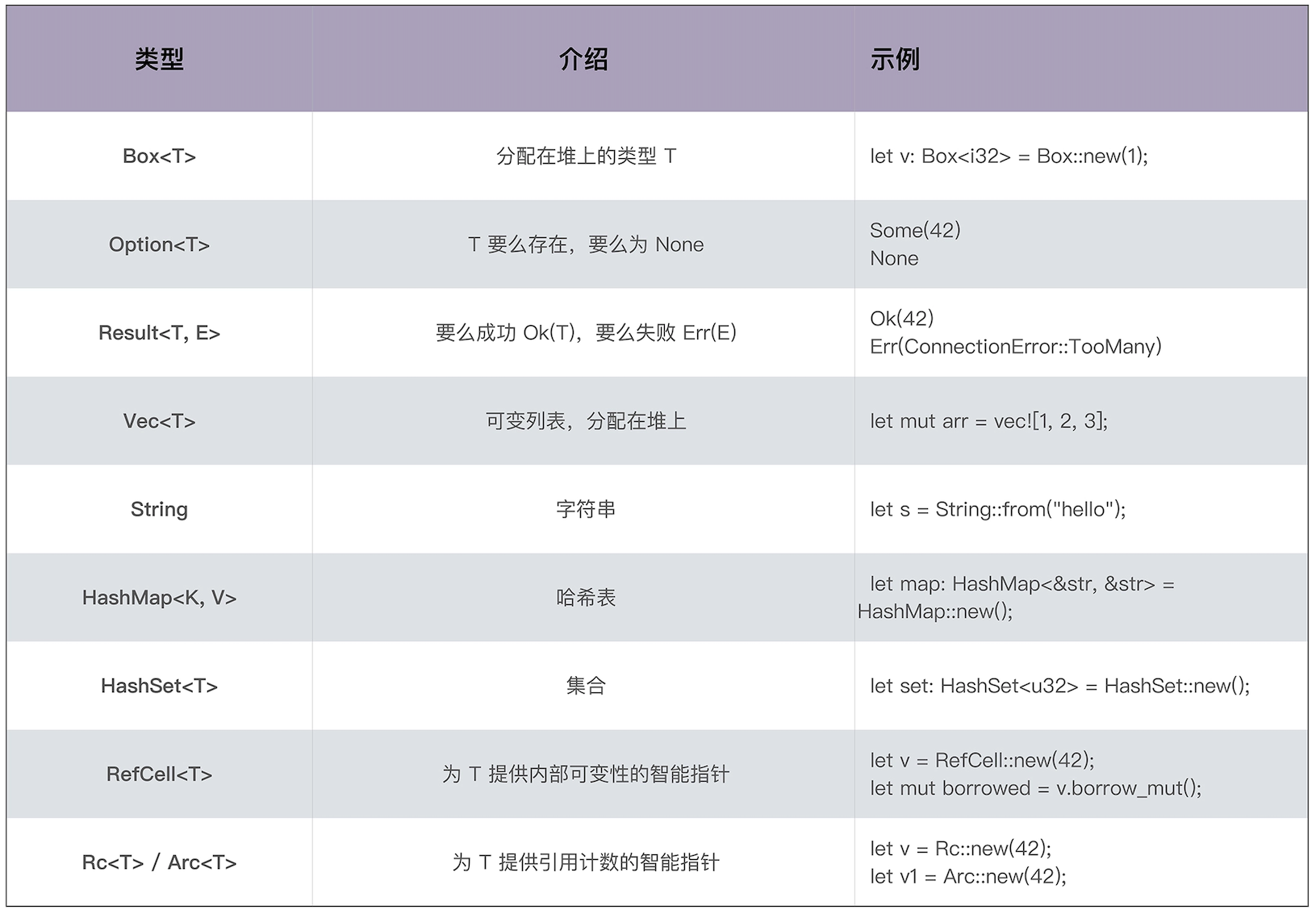
组合类型
- 结构体(structure type) -- struct
- 标签联合(tagged union) -- enum
# 指针和引用
- 指针是一个持有内存地址的值,可以通过 derefence 来访问它指向的内存地址,理论上可以解引用到任意数据类型。
- 比正常指针携带更多信息的指针称为胖指针。
# 代码
# 函数,方法,闭包
- 函数也是对代码中重复行为的抽象。
- 面向对象的编程语言中,在类或者对象中定义的函数,被称为方法(method)。方法往往和对象的指针发生关系
- 闭包引用的上下文中的自由变量,会被捕获到闭包的结构中,成为闭包类型的一部分。
# 接口,虚表
- 作为一个抽象层,接口将使用方和实现方隔离开来,使两者不直接有依赖关系,大大提高了复用性和扩展性
- 在生成这个引用的时候,我们需要构建胖指针,除了指向数据本身外,还需要指向一张涵盖了这个接口所支持方法的列表。这个列表,就是我们熟知的虚表(virtual table)。
- 虚表一般存储在堆上 ???
- 虚表是每个 impl TraitA for TypeB {} 时就会编译出一份。
- 比如 String 的 Debug 实现, String 的 Display 实现各有一份虚表,它们在编译时就生成并放在了二进制文件中(大多是 RODATA 段中)。
- 所以虚表是每个 (Trait, Type) 一份。并且在编译时就生成好了
# 运行方式
# 同步,异步
# 编程范式
# 泛型编程
# 缺陷
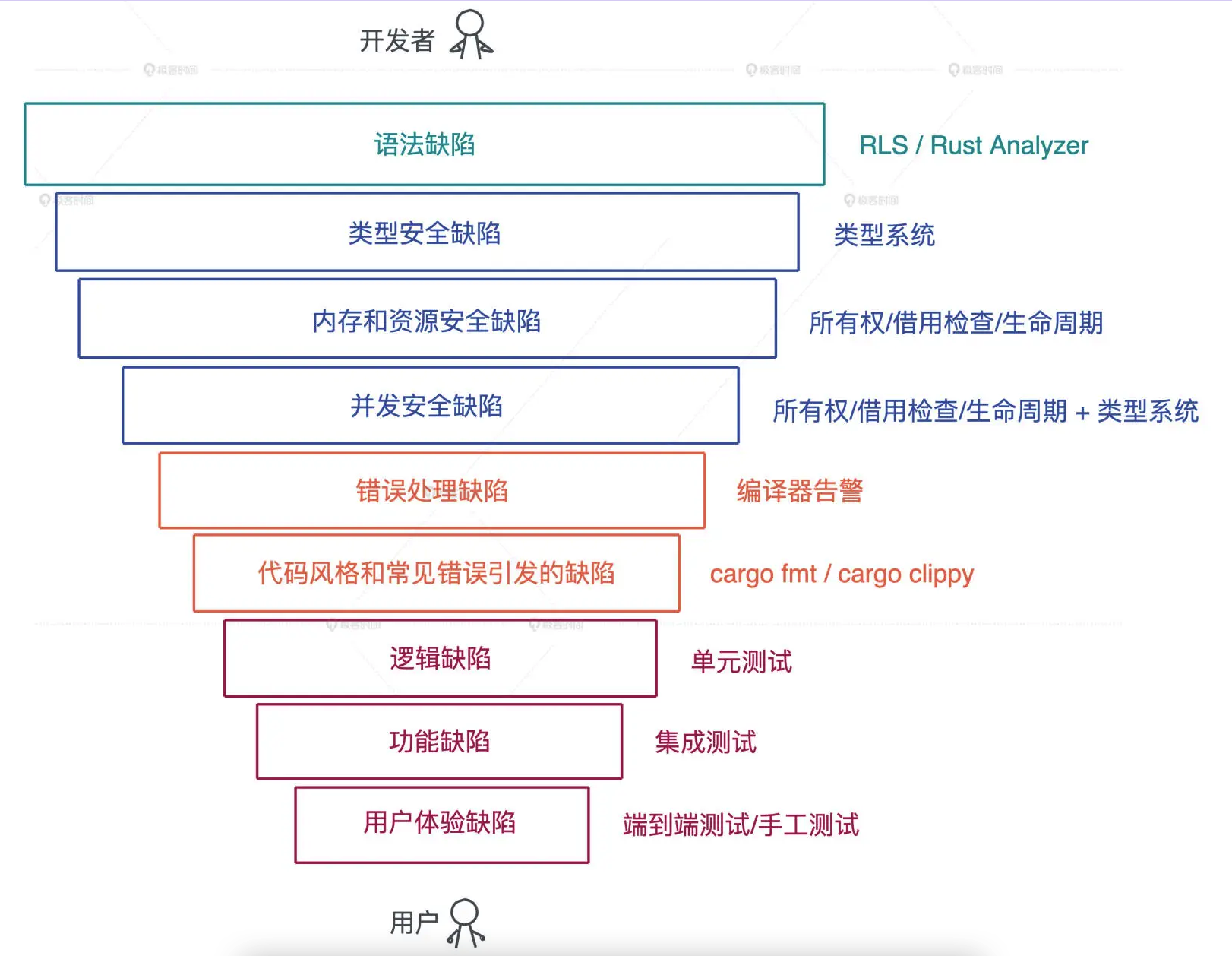
# 学习资料
- rust book (opens new window)
- rustnomicon rust 死灵书 (opens new window)
- docs.rs (opens new window)
- 标准库文档 (opens new window)
# 基础篇
- Rust 是一门基于表达式(expression-based)的语言 Rust is an expression-oriented language.
- 语句(Statements)是执行一些操作但不返回值的指令。表达式(Expressions)计算并产生一个值
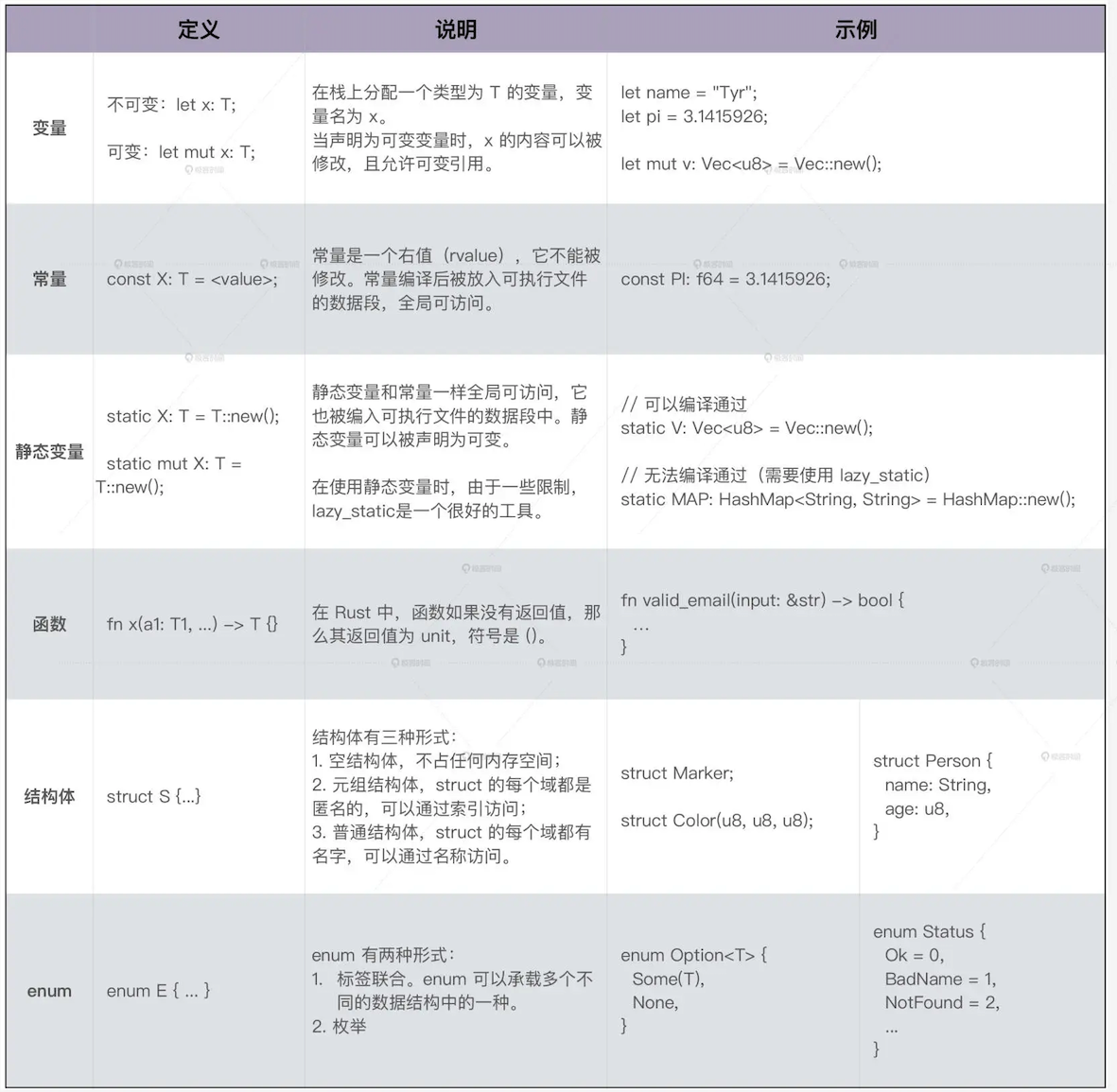
# 基本语法和基础数据类型
- 变量类型一般可以省略;
- const/static 变量必须声明类型;
- 函数参数的类型和返回值的类型都必须显示定义;
- 宏编程的主要流程就是实现若干 From 和 TryFrom
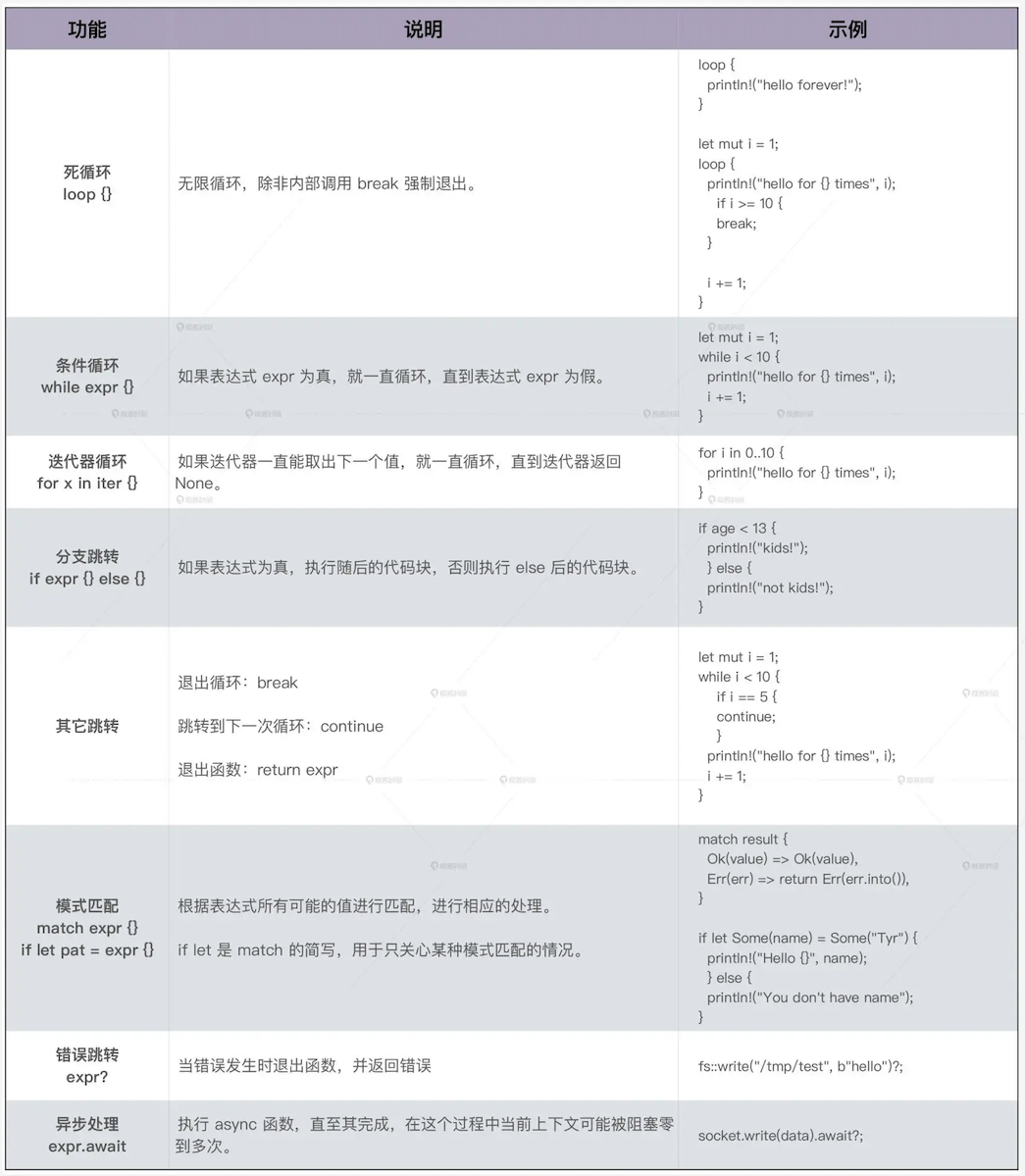
# 所有权和生命周期
核心点:Rust 通过单一所有权来限制任意引用的行为
- Copy trait 与 Drop trait 不能共存。
- 所有权转移时,优先使用 copy 语义, 默认使用 move 语义。
# 所有权规则
- 一个值只能被一个变量所拥有,这个变量被称为所有者
- 一个值同一时刻只能有一个所有者
- 当所有者离开作用域,其拥有的值被丢弃
# Move 语义:
- 赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
# Copy 语义和 Clone 语义
- 符合 Copy 语义的类型,在你赋值或者传参时,值会自动按位拷贝。
- 原生类型,包括函数、不可变引用和裸指针实现了 Copy;
- 数组和元组,如果其内部的数据结构实现了 Copy,那么它们也实现了 Copy;
- 可变引用没有实现 Copy;
- 非固定大小的数据结构,没有实现 Copy。
- Copy 语义仅拷贝栈上的内存。
- Clone trait 是 copy 的 super trait, 深拷贝, 深拷贝得到的堆内存需用通过 Drop trait 来释放。
- 任何有资源需要释放(Drop trait)的数据结构,都无法实现 Copy trait
# Borrow 语义
- Borrow 语义通过引用语法(& 或者 &mut)来实现; 在 Rust 下,所有的引用都只是借用了“临时使用权”,它并不破坏值的单一所有权约束。
- 默认情况下,Rust 的借用都是只读的;
- Rust 所有的参数传递都是传值;
- 借用的生命周期及其约束: 借用不能超过(outlive)值的生存期。
- 在一个作用域内,仅允许一个活跃的可变引用
- 在一个作用域内,活跃的可变引用(写)和只读引用(读)是互斥的,不能同时存在。
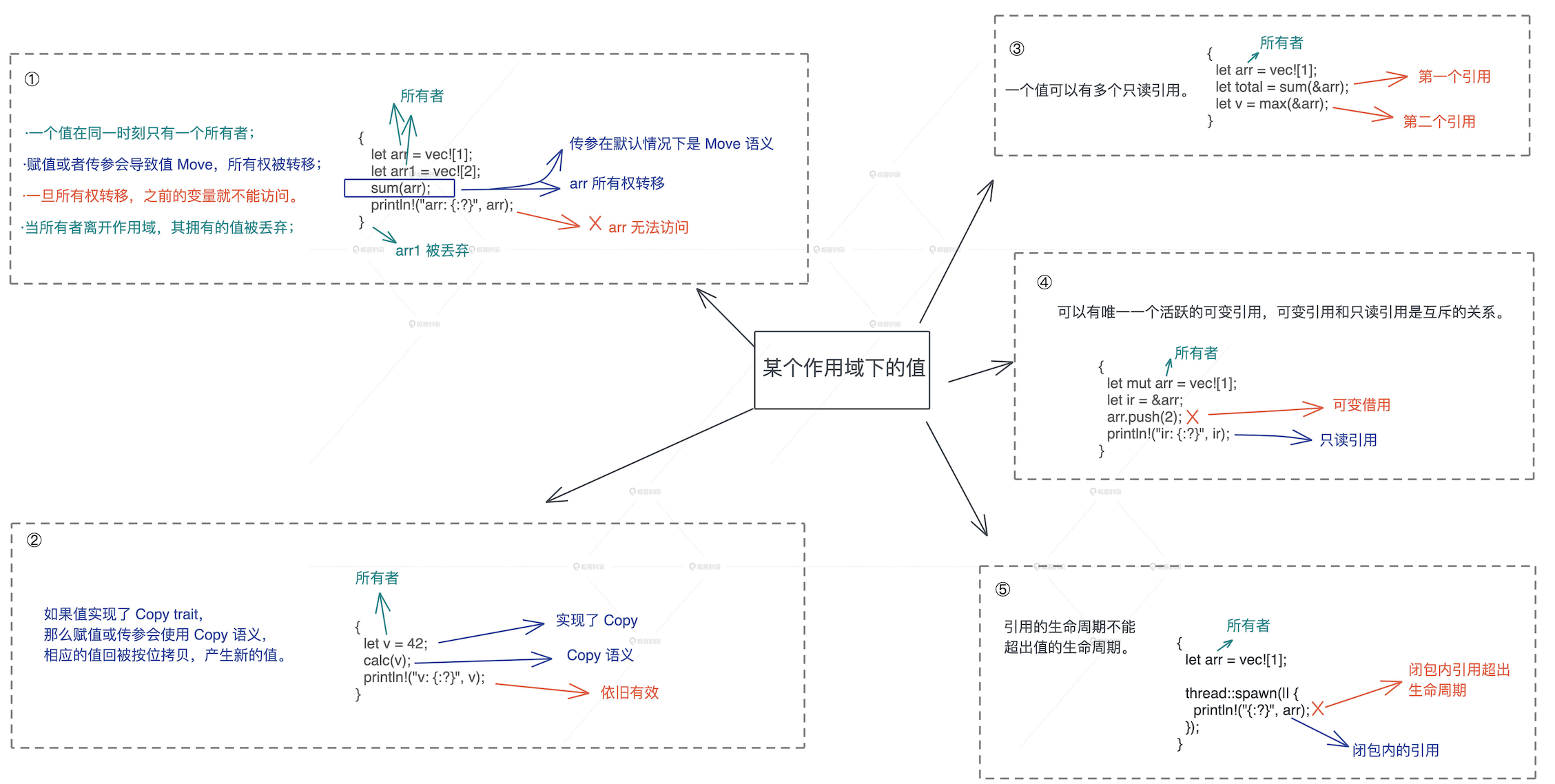
# 多个所有者
- Rust 处理很多问题的思路:编译时,处理大部分使用场景,保证安全性和效率;运行时,处理无法在编译时处理的场景,会牺牲一部分效率,提高灵活性。
- Arc(Atomic Reference Counter);
- Rc(Reference Counter): 对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。Rc 是一个只读的引用计数器
- Box::leak(),它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。
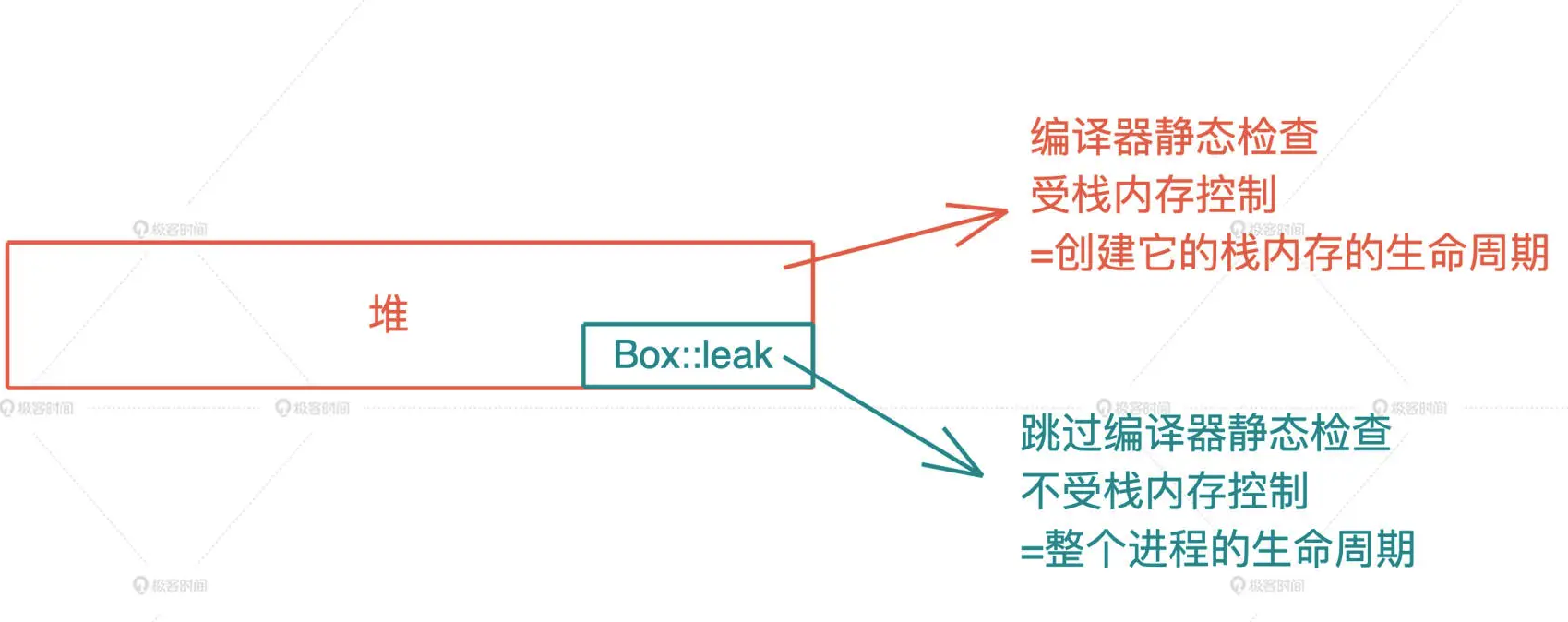
# 内部可变性
Rc<RefCell<T>>针对单线程Arc<Mutex<T>>/Arc<RwLock<T>>针对多线程环境
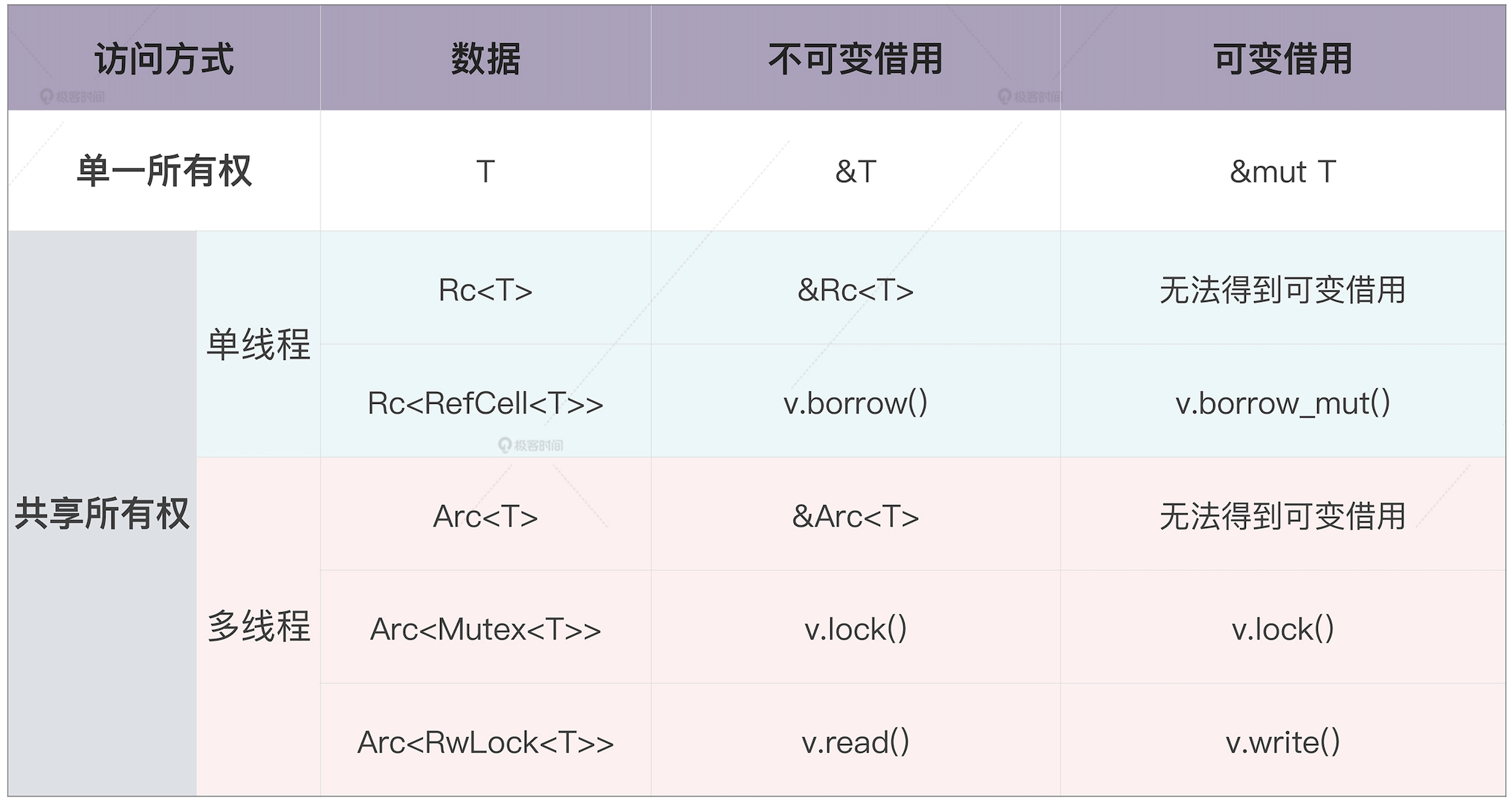
# 生命周期
- 一般来说,堆内存的生命周期,会默认和其栈内存的生命周期绑定在一起。
- 生命周期参数,描述的是参数和参数之间、参数和返回值之间的关系,并不改变原有的生命周期。
- 所有引用类型的参数都有独立的生命周期 'a 、'b 等。
- 如果只有一个引用型输入,它的生命周期会赋给所有输出。
- 如果有多个引用类型的参数,其中一个是 self,那么它的生命周期会赋给所有输出。
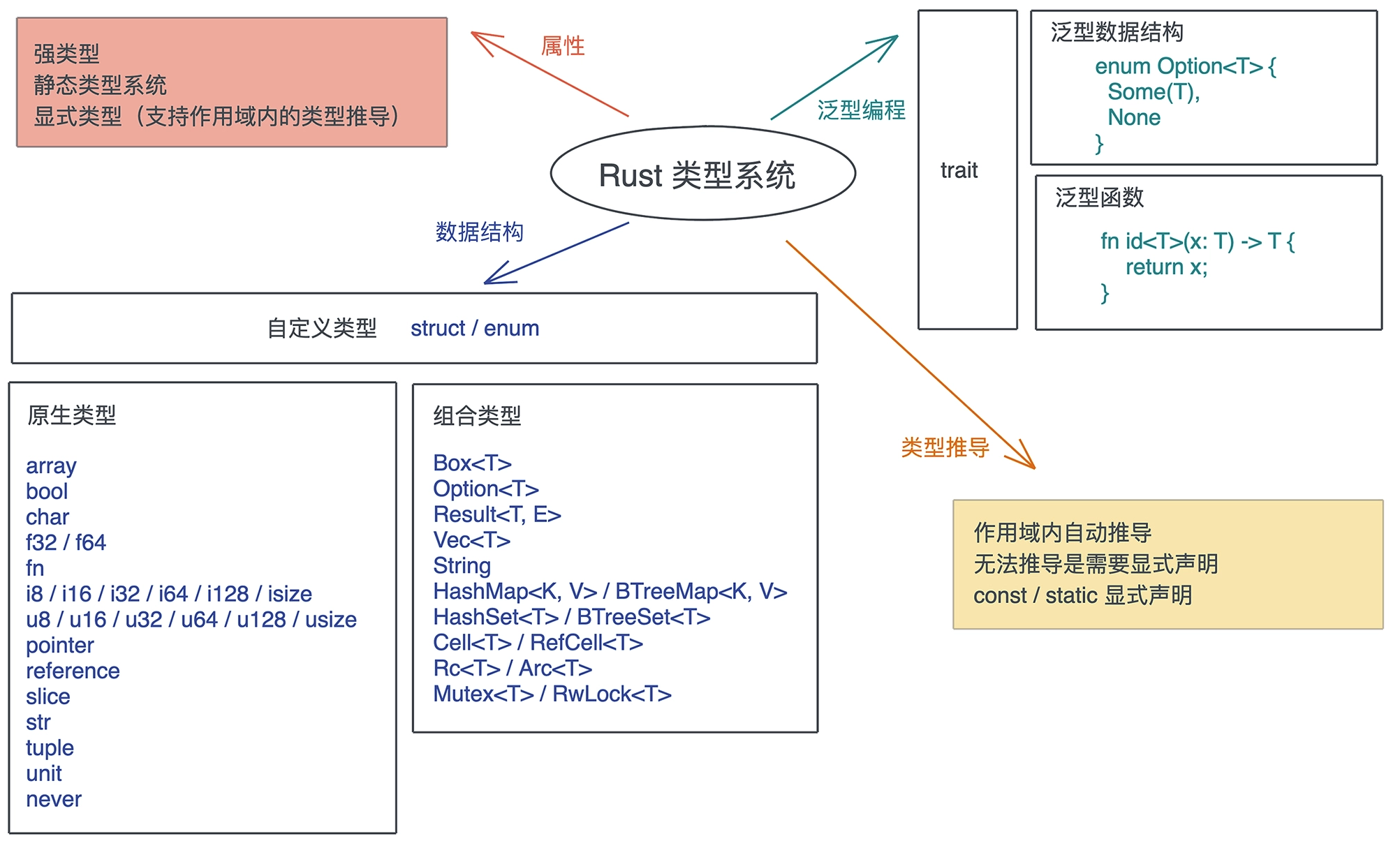
# 类型系统
- 类型系统是一种对类型进行定义、检查和处理的工具;
- 类型,是对值的区分,它包含了值在内存中的长度、对齐以及值可以进行的操作等信息;
- Rust 下的内存安全更严格:代码只能按照被允许的方法和被允许的权限,访问它被授权访问的内存;
- Rust 中除了 let / fn / static / const 这些定义性语句外,都是表达式,而一切表达式都有类型;
- unit 是只有一个值的类型,它的值和类型都是 ();
- 即使上下文中含有类型的信息,也需要开发者为变量提供类型,比如常量和静态变量的定义;需要明确的类型声明。
原生类型:
 组合类型:
组合类型:
 Rust 类型系统:
Rust 类型系统:
# 多态
- 参数多态:代码操作的类型是一个满足某些约束的参数,而非具体的类型;=> 泛型 Rust Generic
- 特设多态: 一般指函数的重载;包括运算符重载 => Rust Trait
- 子类型多态:在运行时,子类型可以被当成父类型使用。=> Rust Trait Object
# 泛型数据结构
- 函数,是把重复代码中的参数抽取出来;
- 泛型,是把重复数据结构中的参数抽取出来;
生命周期标注也是泛型的一部分
# 单态化
- 好处: 泛型函数的调用是静态分派(static dispatch);
- 缺点 1: 编译速度慢;一个泛型函数,编译器需要找到所有用到的不同类型,一个个编译;
- 缺点 2: 编译出的二进制代码会比较大,存在 N 份。
- 缺点 3: 代码以二进制分发会损失泛型的信息。单态化之后,原本的泛型信息就被丢弃了。
# trait
- 定义了类型使用这个接口的行为;
- 在 trait 中,方法可以有缺省的实现;
- 允许用户把错误类型延迟到 trait 实现时才决定,这种带有关联类型的 trait 比普通 trait,更加灵活,抽象度更高
- trait 的”继承“: trait B 在定义时可以使用 trait A 中的关联类型和方法
# Trait Object
表现为&dyn Trait 或者
Box<dyn Trait>:(动态分派(dynamic dispatch));底层逻辑就是胖指针:数据本身+虚函数表 vtable;
如果 trait 所有的方法,返回值是 Self(trait object 产生时原来的类型会被抹去) 或者携带泛型参数(trait object 是运行时的产物),那么这个 trait 就不能产生 trait object。
rust会为实现了trait object类型的trait实现,生成相应的vtable,放在可执行文件中(一般在TEXT或RODATA段)。

# Traits

send/sync: 如果一个类型 T: Send,那么 T 在某个线程中的独占访问是线程安全的;如果一个类型 T: Sync,那么 T 在线程间的只读共享是安全的;
Clone 是深度拷贝,栈内存和堆内存一起拷贝;
Copy 是按位浅拷贝,与 Drop 互斥;
不支持 Send / Sync 的数据结构主要有:
- 裸指针 *const T / *mut T。它们是不安全的,所以既不是 Send 也不是 Sync。
- UnsafeCell 不支持 Sync。也就是说,任何使用了 Cell 或者 RefCell 的数据结构不支持 Sync。
- 引用计数 Rc 不支持 Send 也不支持 Sync。所以 Rc 无法跨线程。
只需要实现
From<T>,Into<T>会自动实现;
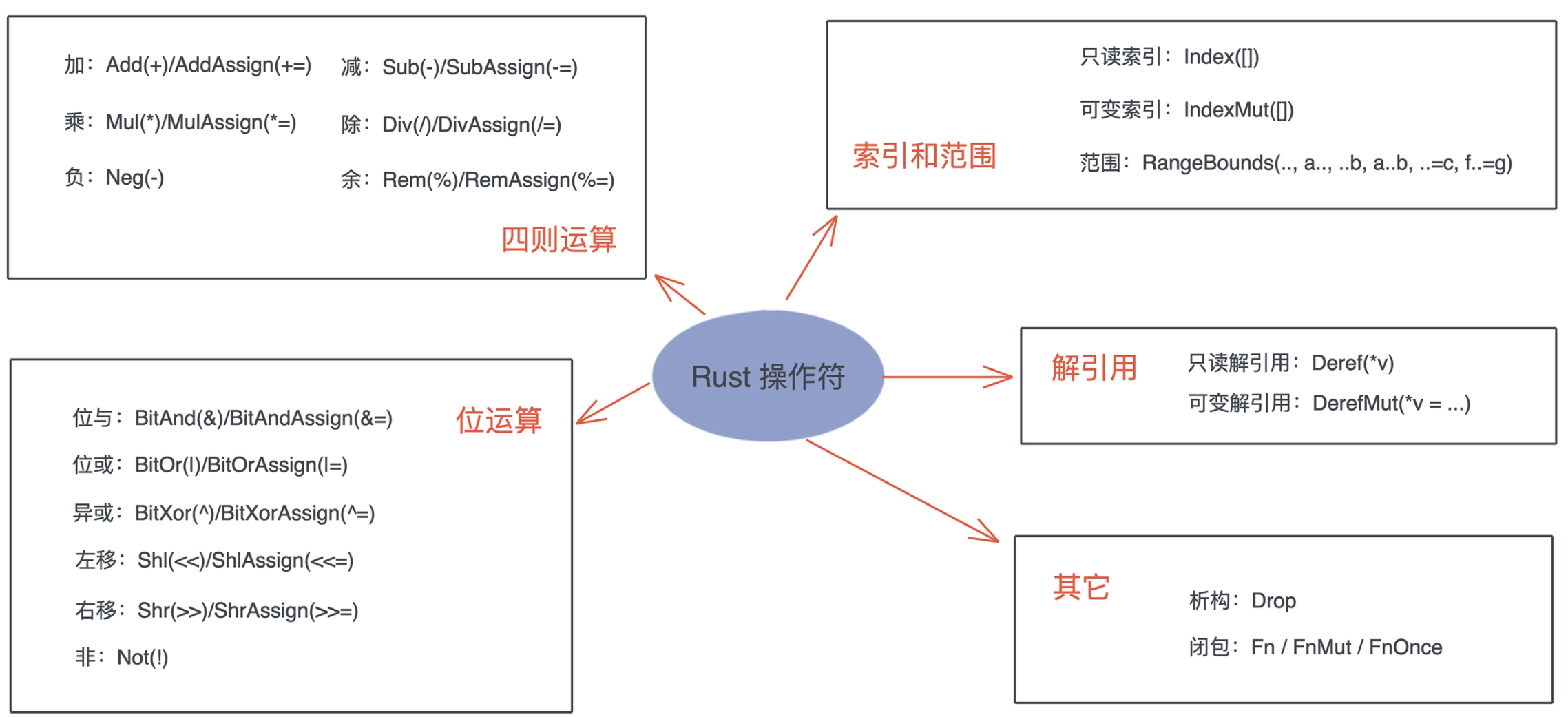
# 延迟绑定
- 从数据的角度看,[数据结构]是[具体数据]的延迟绑定,[泛型结构]是[具体数据结构]的延迟绑定;
- 从代码的角度看,[函数]是一组实现某个功能的[表达式]的延迟绑定,[泛型函数]是[函数]的延迟绑定;
- [trait] 是[行为]的延迟绑定
# 数据结构
- 指针是一个持有内存地址的值,可以通过解引用来访问它指向的内存地址,理论上可以解引用到任意数据类型;
- 引用是一个特殊的指针,它的解引用访问是受限的,只能解引用到它引用数据的类型,不能用作它用

# 智能指针:
- 是一个胖指针;
- 智能指针String 对堆上的值具有所有权,而普通胖指针&str没有所有权;
- 在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针
# Box<T>在堆上创建内存
# Cow<'a, B>提供写时克隆
# 分发手段
- 使用泛型参数做静态分发
- 使用 trait object 做动态分发
- 这种根据 enum 的不同状态来进行统一分发的方法是第三种分发手段,其效率是动态分发的数十倍。
# MutexGuard<T>用于数据加锁
- 通过 Drop trait 来确保,使用到的内存以外的资源在退出时进行释放
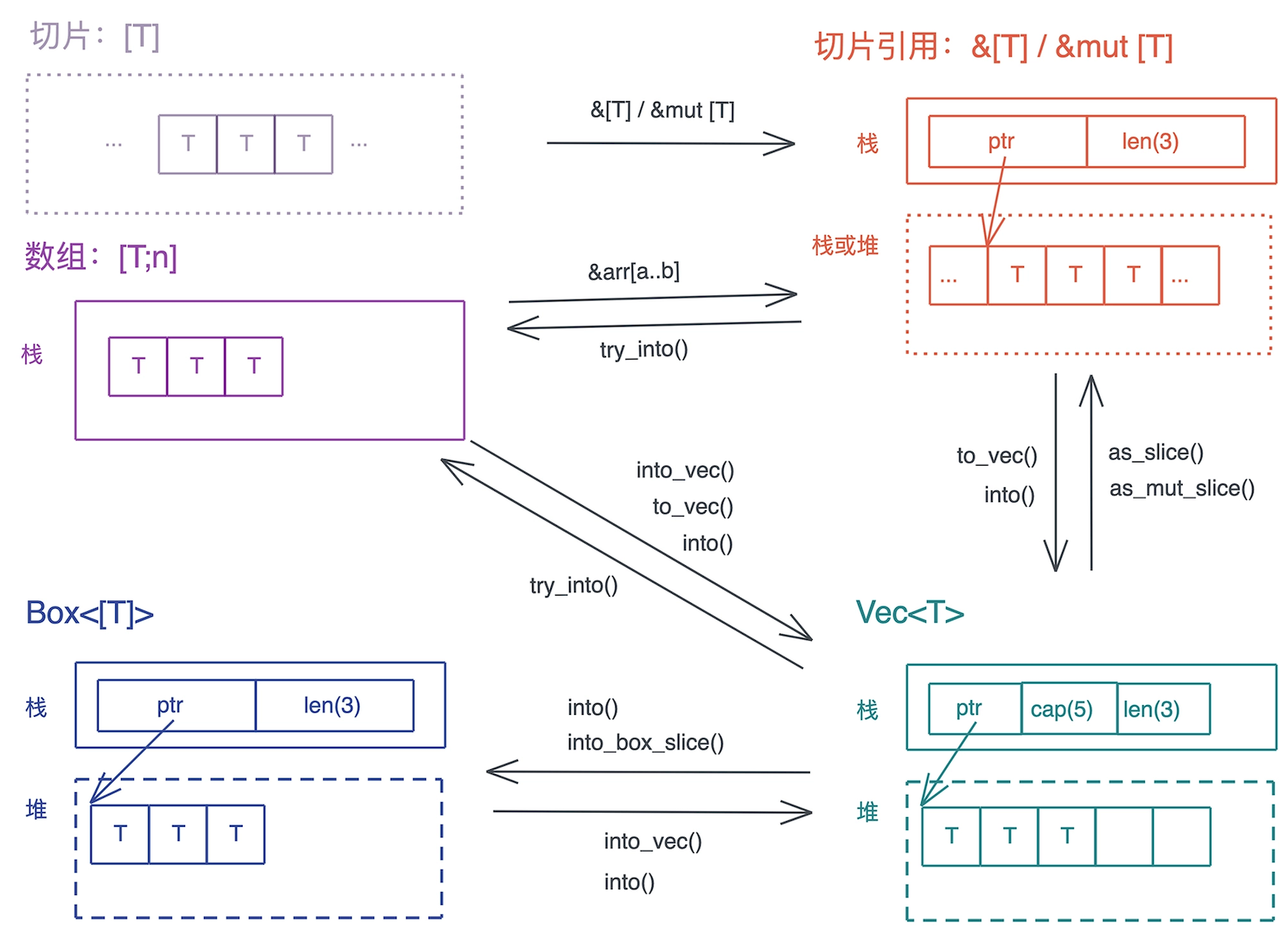
# 切片 Slice
&[T]只读切片,只是一个借用&mut[T]可写的切片Box<[T]>堆上分配的切片: 而Box<[T]>一旦生成就固定下来,没有 capacity,也无法增长;对数据具有所有权。Vec 可以通过 into_boxed_slice() 转换成
Box<[T]>,Box<[T]>也可以通过 into_vec() 转换回 Vec;当我们需要在堆上创建固定大小的集合数据,且不希望自动增长,那么,可以先创建 Vec,再转换成
Box<[T]>;Box<[T]>和&[T]的区别:Box<[T]>指针指向的是堆内存数据;&[T]指针指向的数据可以是堆、栈内存数据;Box<[T]>对数据具有所有权;&[T]只是一个借用;
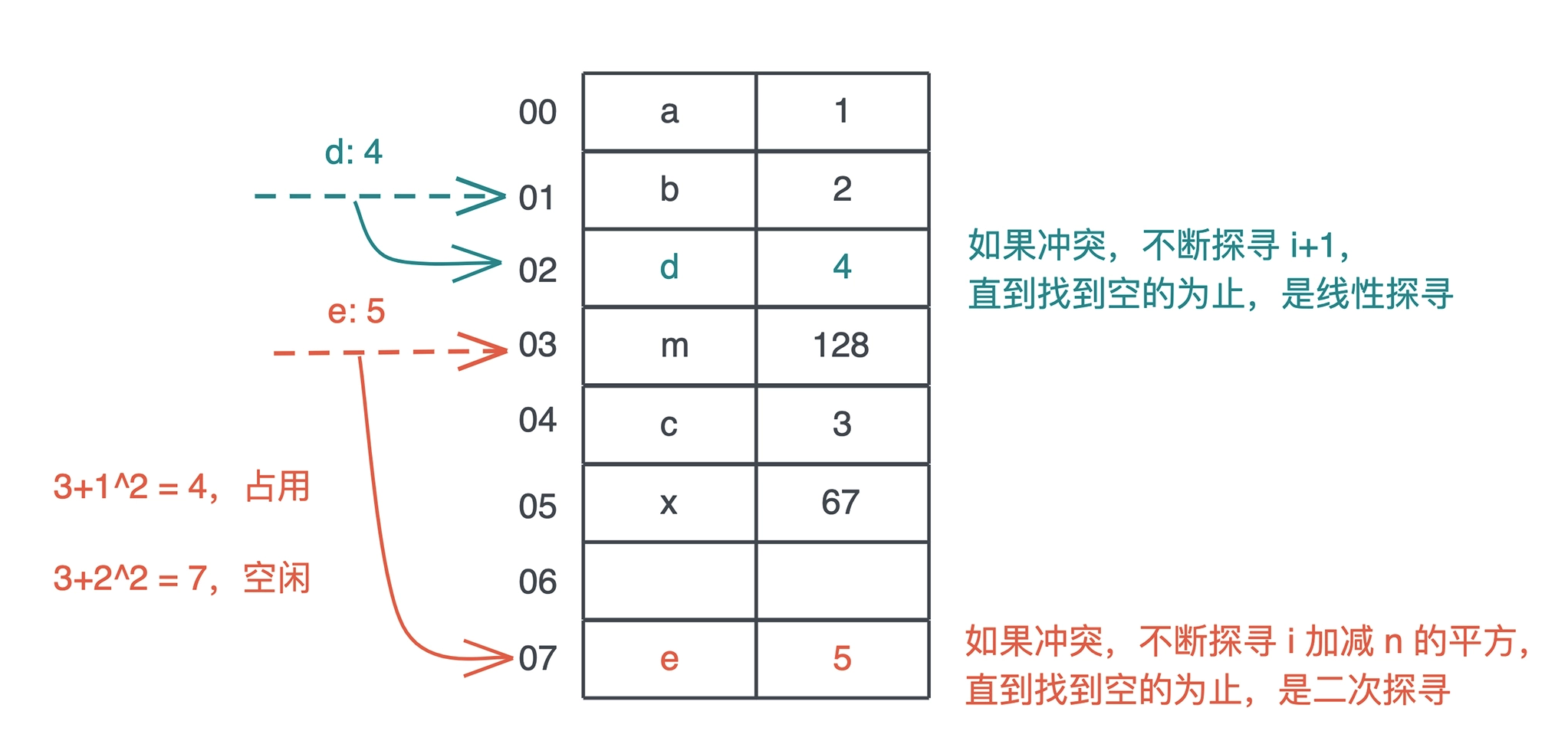
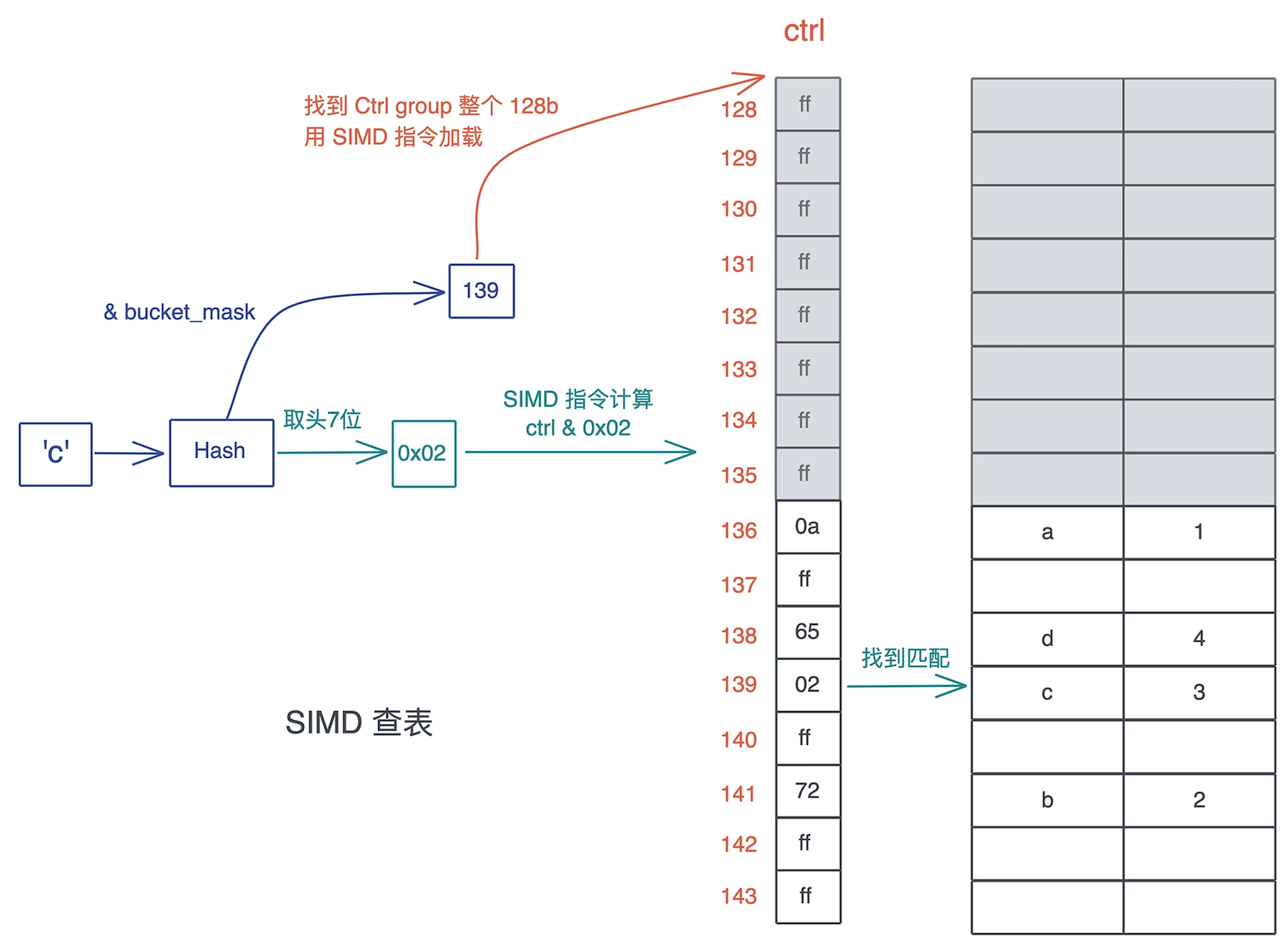
# 哈希表
- 哈希表最核心的特点就是:巨量的可能输入和有限的哈希表容量。
- Rust 哈希表算法的设计核心:
- 二次探查(quadratic probing)
- SIMD(单指令多数据) 查表(Single Instruction Multiple Data lookup)
- 解决哈希冲突机制
- 链地址法(chaining)
- 开放寻址法(open addressing)
- 通过 shrink_to_fit / shrink_to 释放掉不需要的内存
哈希冲突解决机制
SIMD 查表
# 错误处理的主流方法
- 返回值
- 异常处理
- 类型系统
- 在 Rust 代码中,如果你只想传播错误,不想就地处理,可以用 ? 操作符
- 使用 Option 和 Result 是 Rust 中处理错误的首选
- 立刻暴露 Panic!, catch_unwind!
# 闭包
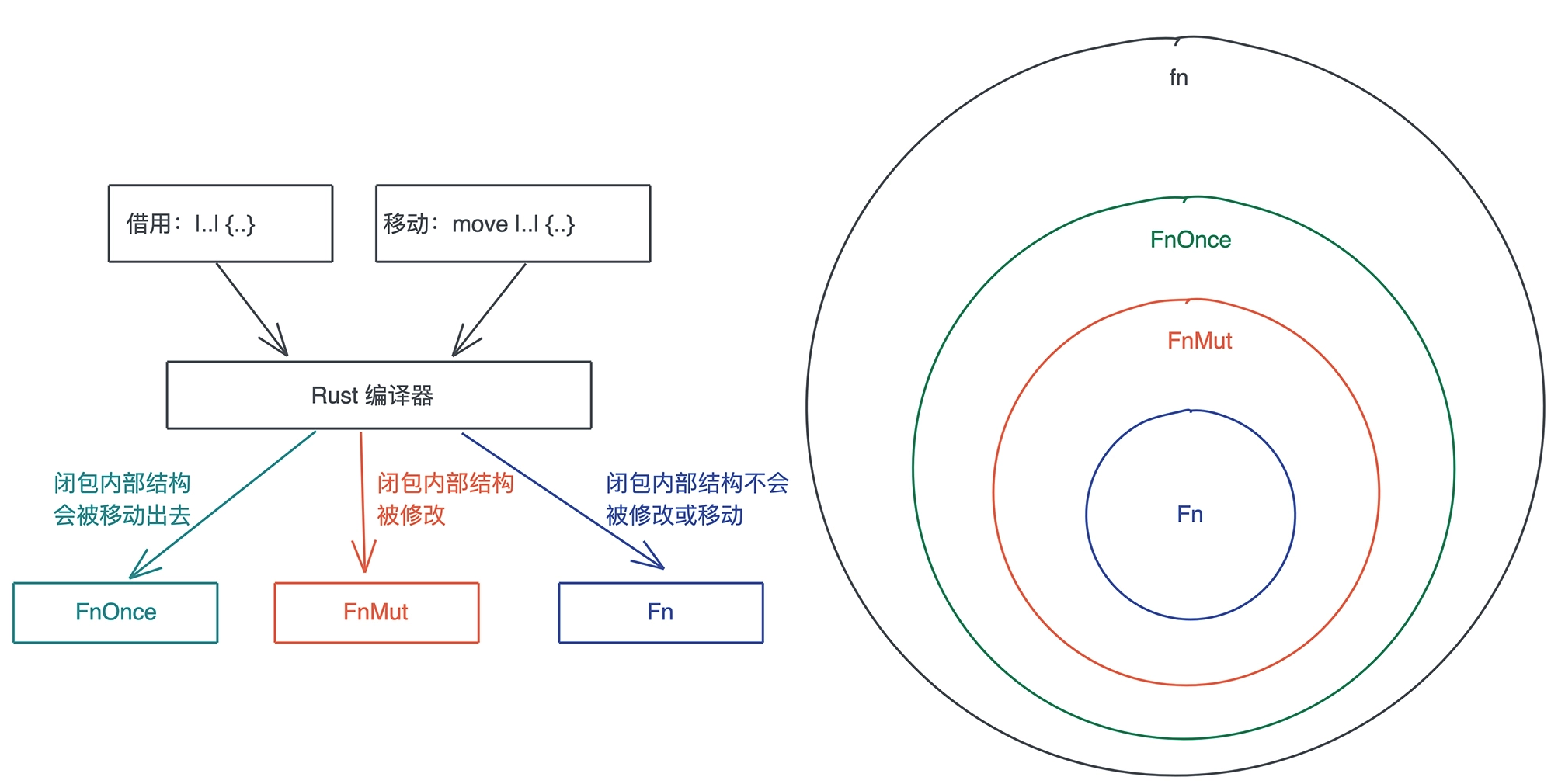
- 闭包是一种匿名类型,一旦声明,就会产生一个新的类型(调用闭包时可以直接和代码对应),但这个类型无法被其它地方使用。这个类型就像一个结构体,会包含所有捕获的变量。
- 不带 move 时,闭包捕获的是对应自由变量的引用;
- 带 move 时,对应自由变量的所有权会被移动到闭包结构中
- 闭包的大小跟参数、局部变量都无关,只跟捕获的变量有关,闭包捕获的变量都存储在栈上。
- 闭包是存储在栈上(没有堆内存分配),并且除了捕获的数据外,闭包本身不包含任何额外函数指针指向闭包的代码。
- 闭包的调用效率和函数调用几乎一致
# 进阶篇
# 类型系统
# 泛型
- 架构师的工作不是作出决策,而是尽可能久地推迟决策,在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。
- 通过使用泛型参数,BufReader 把决策交给使用者。
- 泛型参数三种常见的使用场景:
- 使用泛型参数延迟数据结构的绑定;
- 使用泛型参数和 PhantomData,声明数据结构中不直接使用但在实现过程中需要用到的类型;
- 使用泛型参数让同一个数据结构对同一个 trait 可以拥有不同的实现。
- PhantomData:
- 被广泛用在处理,数据结构定义过程中不需要,但是在实现过程中需要的泛型参数;
- 在定义数据结构时,对于额外的、暂时不需要的泛型参数,用 PhantomData 来“拥有”它们,这样可以规避编译器的报错。
- 实际长度为零,是个 ZST(Zero-Sized Type), 类型标记。
# Trait Object
- 使用 Trait Object 是有额外的代价的,首先这里有一次额外的堆分配,其次动态分派会带来一定的性能损失
- 当在某个上下文中需要满足某个 trait 的类型,且这样的类型可能有很多,当前上下文无法确定会得到哪一个类型时,我们可以用 trait object 来统一处理行为。
- 和泛型参数一样,trait object 也是一种延迟绑定,它让决策可以延迟到运行时,从而得到最大的灵活性。
- 后果是执行效率的打折。在 Rust 里,函数或者方法的执行就是一次跳转指令,而 trait object 方法的执行还多一步,它涉及额外的内存访问,才能得到要跳转的位置再进行跳转,执行的效率要低一些。
- 返回/线程间传递 trait object 都免不了使用 Box 或者 Arc,会带来额外的堆分配的开销。
# 围绕trait来设计和架构系统
- 软件开发的整个行为,基本上可以说是不断创建和迭代接口,然后在这些接口上进行实现的过程。
- 用trait做桥接
- SOLID原则
- SRP:单一职责原则,是指每个模块应该只负责单一的功能,不应该让多个功能耦合在一起,而是应该将其组合在一起。
- OCP:开闭原则,是指软件系统应该对修改关闭,而对扩展开放。
- LSP:里氏替换原则,是指如果组件可替换,那么这些可替换的组件应该遵守相同的约束,或者说接口。
- ISP:接口隔离原则,是指使用者只需要知道他们感兴趣的方法,而不该被迫了解和使用对他们来说无用的方法或者功能。
- DIP:依赖反转原则,是指某些场合下底层代码应该依赖高层代码,而非高层代码去依赖底层代码。
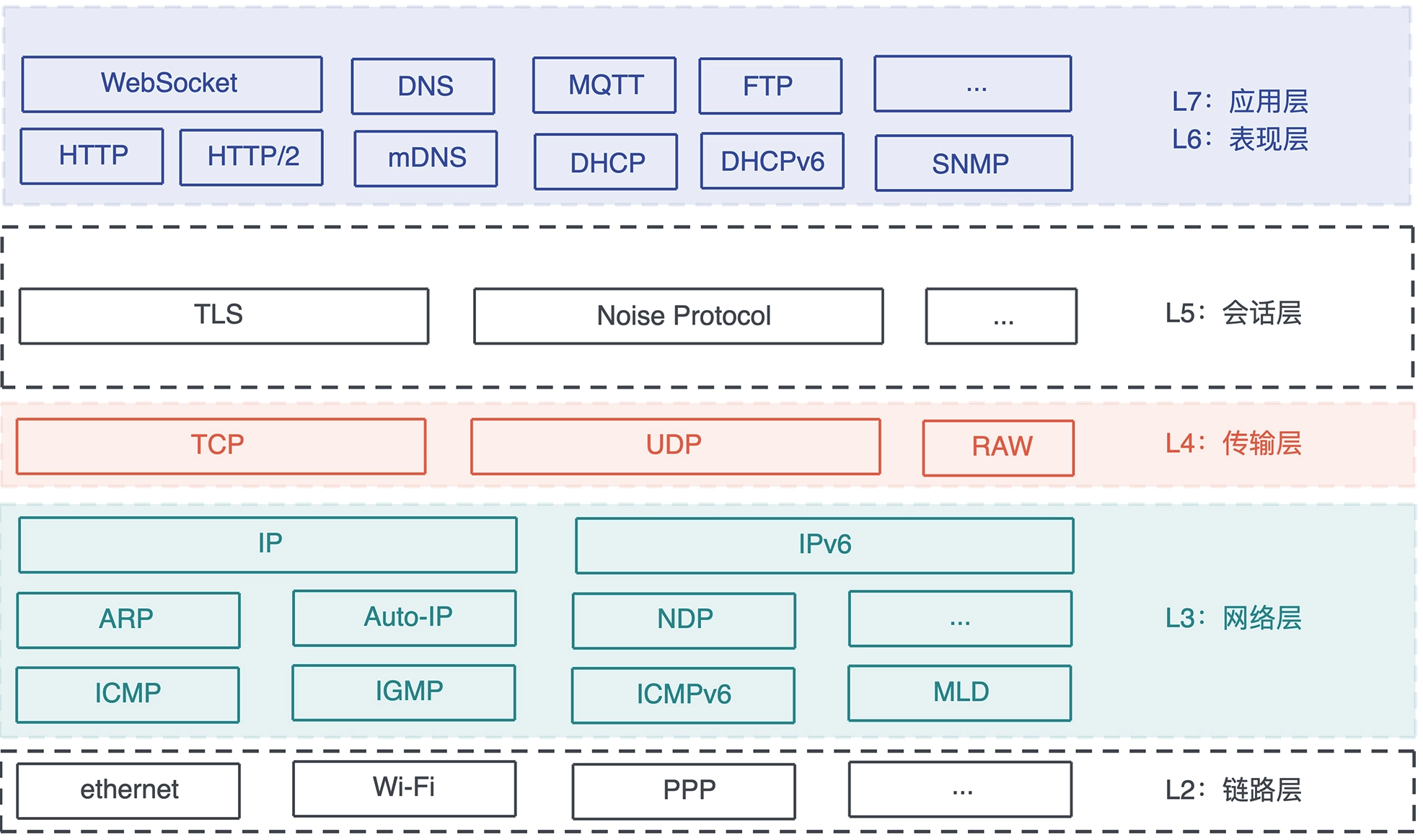
# 网络开发
应表会传网链 物
# Unsafe Rust
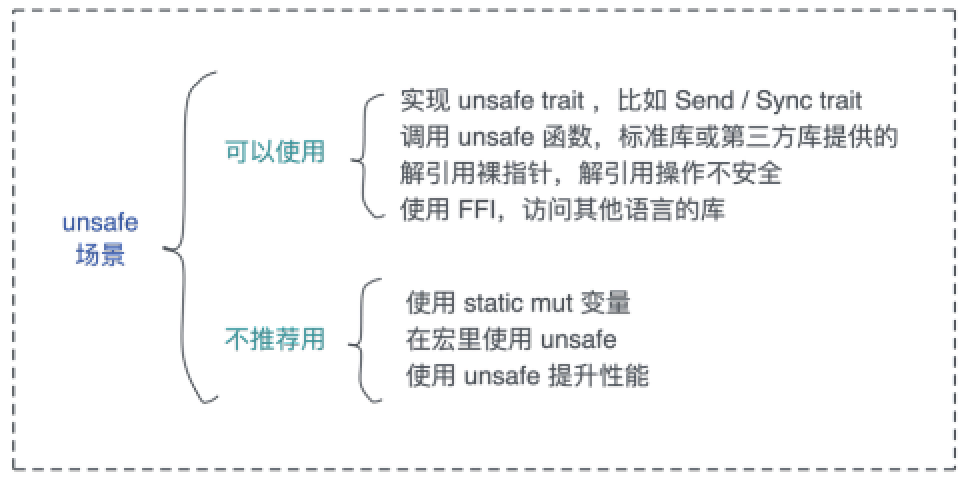
可以使用、也推荐使用 unsafe 的场景
- 实现 unsafe trait:
- 主要是Send / Sync 这两个 trait;
- 任何 trait,只要声明成 unsafe,它就是一个 unsafe trait;
- unsafe trait 是对 trait 的实现者的约束
- unsafe fn 是函数对调用者的约束,需要加 unsafe block
- 调用已有的 unsafe 函数:
- 需要加 unsafe block;
- 定义 unsafe 函数,在其中调用 unsafe 函数;
- 对裸指针做解引用
- 使用 FFI
不推荐的使用 unsafe 的场景
- 访问或者修改可变静态变量
- 任何需要 static mut 的地方,都可以用 AtomicXXX / Mutex / RwLock 来取代。
- 在宏里使用 unsafe
- 使用 unsafe 提升性能
- 而有些时候,即便你能够使用 unsafe 让局部性能达到最优,但作为一个整体看的时候,这个局部的优化可能根本没有意义。
撰写 unsafe 代码
- 一定要用注释声明代码的安全性
# FFI(Foreign Function Interface)
一门语言,如果能跟 C ABI(Application Binary Interface)处理好关系,那么就几乎可以和任何语言互通。
处理 FFI 的注意事项
- 如何处理数据结构的差异?
- 谁来释放内存?
- 如何进行错误处理?
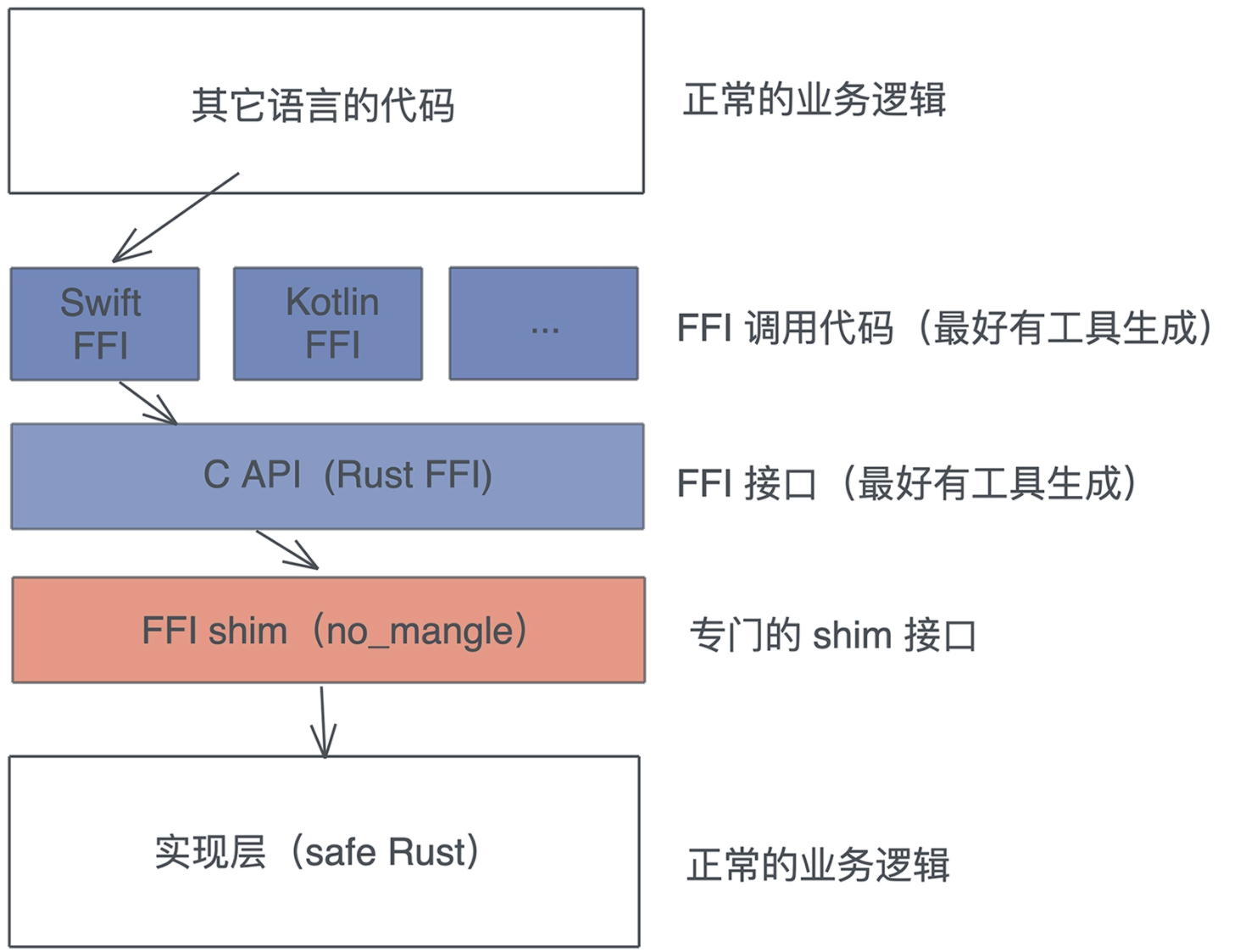
Rust shim 主要做四件事情:
- 提供 Rust 方法、trait 方法等公开接口的独立函数。注意 C 是不支持泛型的,所以对于泛型函数,需要提供具体的用于某个类型的 shim 函数。
- 所有要暴露给 C 的独立函数,都要声明成 #[no_mangle],不做函数名称的改写。
- 数据结构需要处理成和 C 兼容的结构。
- 要使用 catch_unwind 把所有可能产生 panic! 的代码包裹起来。
FFI 的其它方式
- 通过网络:REST API、gRPC
- protobuf 来序列化 / 反序列化要传递的数据
# 并发篇
并发concurrent:轮流处理,多队列一件事;并行parallel:同时执行,多队列多件事;

并发和并行都是对“多任务”处理的描述,其中并发是轮流处理,而并行是同时处理。
在处理并发的过程中,难点并不在于如何创建多个线程来分配工作,在于如何在这些并发的任务中进行同步。
我们来看并发状态下几种常见的工作模式:
- 自由竞争模式、
- map/reduce 模式、
- DAG 模式:
# Atomic
Atomic 是一切并发同步的基础
# Mutex
用来解决这种读写互斥问题的基本工具
# RwLock
# Semaphore
# Condvar
典型场景是生产者 - 消费者模式
在实践中,Condvar 往往和 Mutex 一起使用:Mutex 用于保证条件在读写时互斥,Condvar 用于控制线程的等待和唤醒。
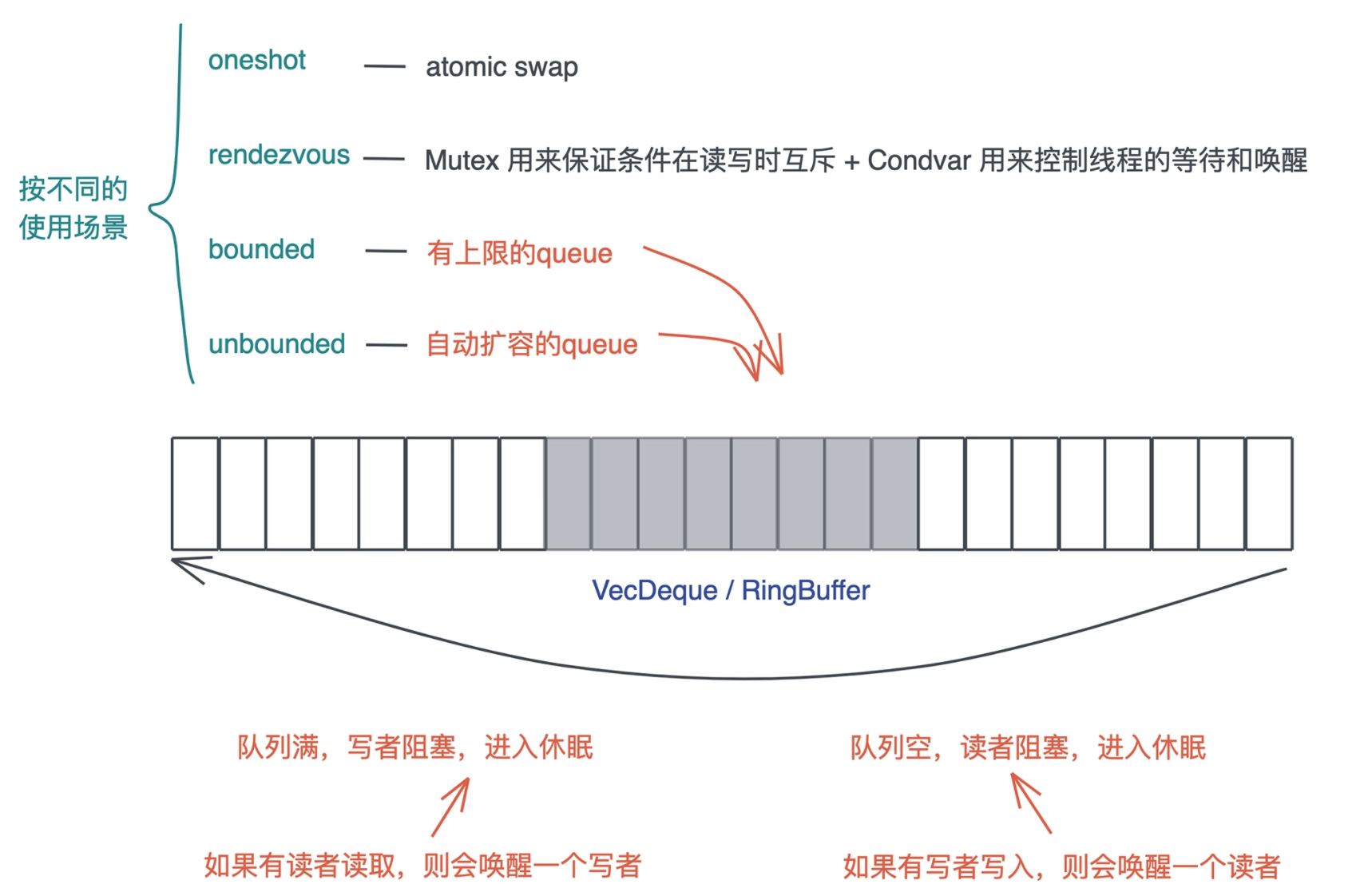
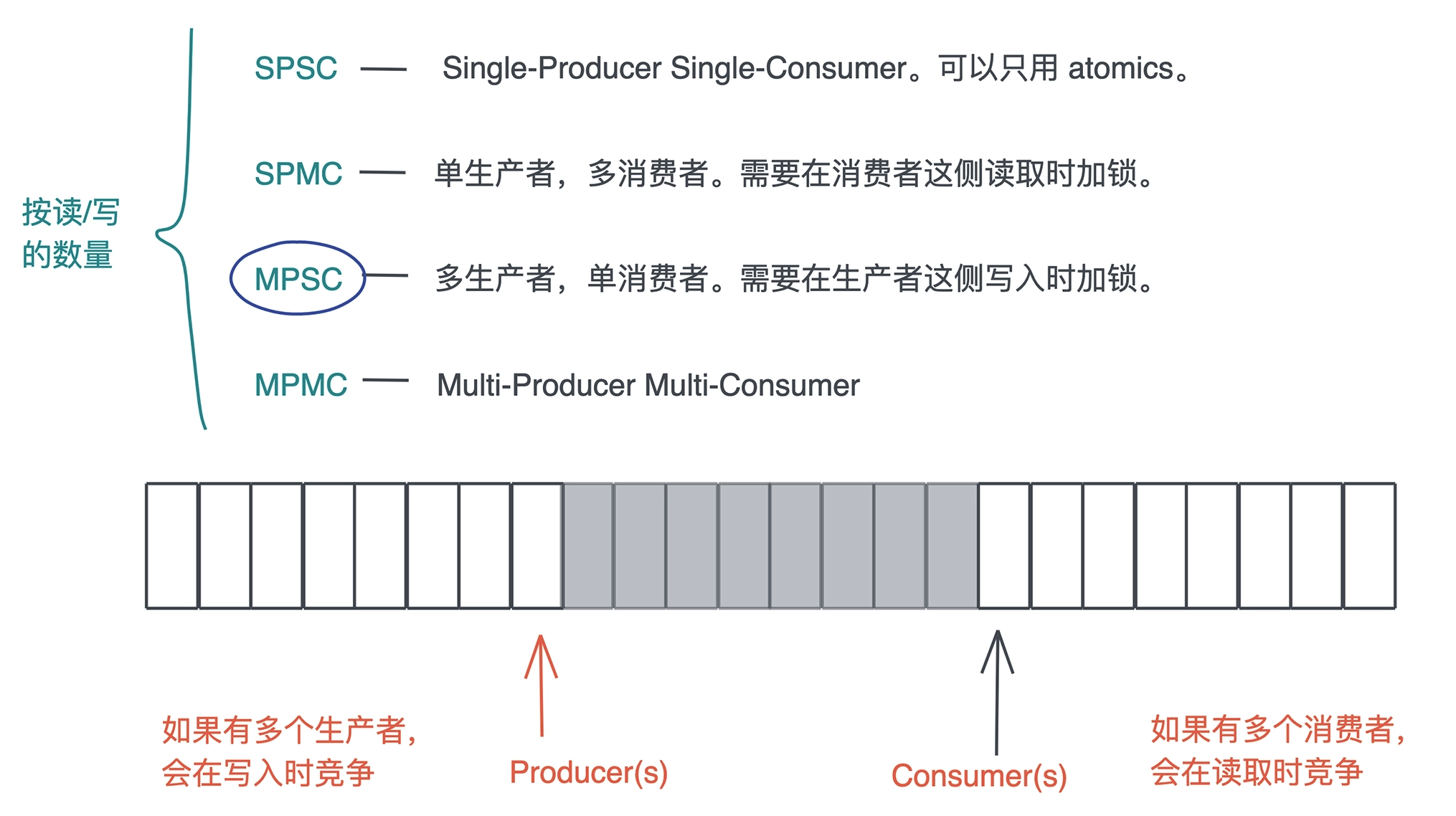
# Channel
Channel 把锁封装在了队列写入和读取的小块区域内,然后把读者和写者完全分离
# Actor
actor 是一种有栈协程。每个 actor,有自己的一个独立的、轻量级的调用栈,以及一个用来接受消息的消息队列(mailbox 或者 message queue),外界跟 actor 打交道的唯一手段就是,给它发送消息。
- Atomic 在处理简单的原生类型时非常有用,如果你可以通过 AtomicXXX 结构进行同步,那么它们是最好的选择。
- 当你的数据结构无法简单通过 AtomicXXX 进行同步,但你又的确需要在多个线程中共享数据,那么 Mutex / RwLock 可以是一种选择。不过,你需要考虑锁的粒度,粒度太大的 Mutex / RwLock 效率很低。
- 如果你有 N 份资源可以供多个并发任务竞争使用,那么,Semaphore 是一个很好的选择。比如你要做一个 DB 连接池。
- 当你需要在并发任务中通知、协作时,Condvar 提供了最基本的通知机制,而 Channel 把这个通知机制进一步广泛扩展开,于是你可以用 Condvar 进行点对点的同步,用 Channel 做一对多、多对一、多对多的同步。
如果说在做整个后端的系统架构时,我们着眼的是:有哪些服务、服务和服务之间如何通讯、数据如何流动、服务和服务间如何同步;那么在做某一个服务的架构时,着眼的是有哪些功能性的线程(异步任务)、它们之间的接口是什么样子、数据如何流动、如何同步。
# Future
# Reactor Pattern(反应器模式)
Reactor Pattern 包含三部分:
- tasks:待处理任务
- Executor: 调度执行tasks
- Reactor: 维护事件队列
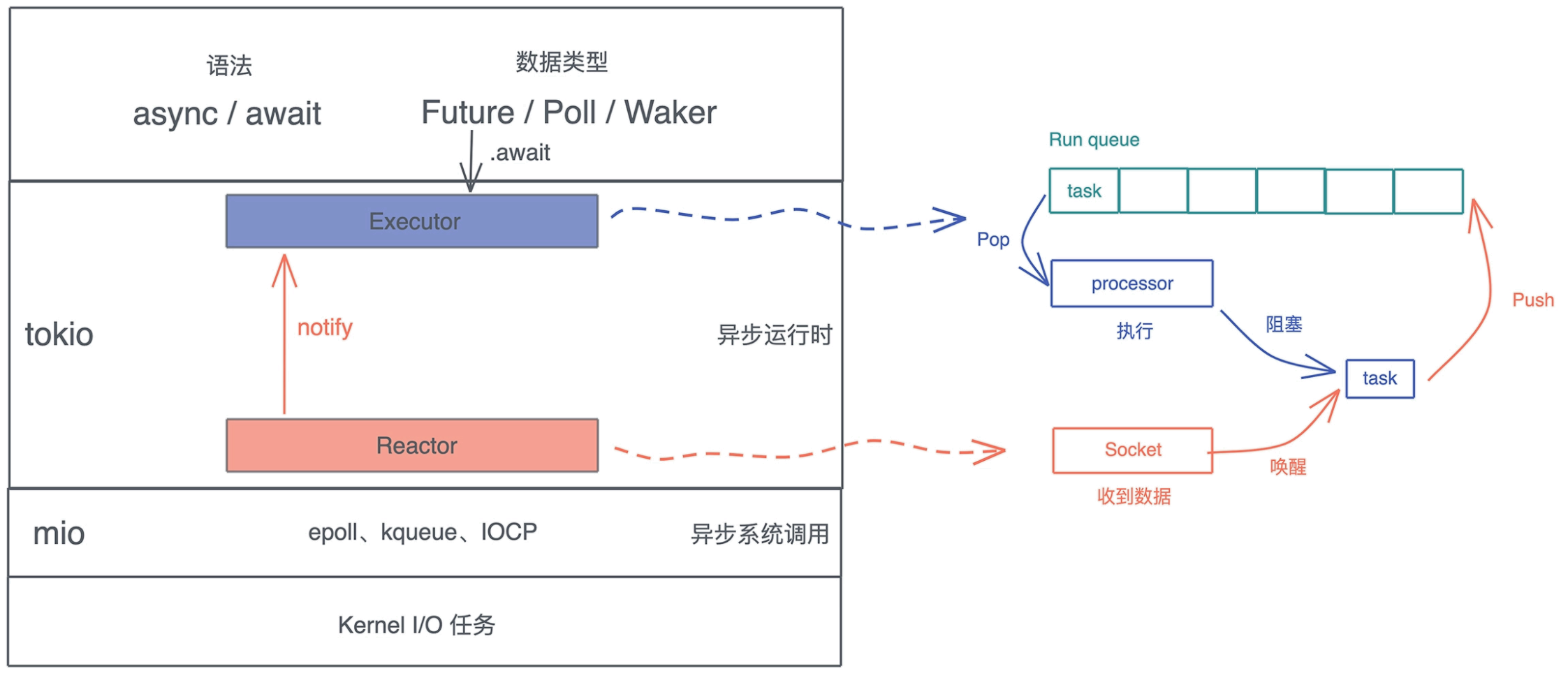
使用 Future 的注意事项
- 我们要避免在异步任务中处理大量计算密集型的工作;
- 在使用 Mutex 等同步原语时,要注意标准库的 MutexGuard 无法跨越 .await,所以,此时要使用对异步友好的 Mutex,如 tokio::sync::Mutex;
- 如果要在线程和异步任务间同步,可以使用 channel。
# 状态机
# Pin
Pin 是为了让某个数据结构无法合法地移动,而 Unpin 则相当于声明数据结构是可以移动的,它的作用类似于 Send / Sync,通过类型约束来告诉编译器哪些行为是合法的、哪些不是。
# 自引用数据结构
# Generator
- rust中的生成器被实现为状态机。计算链的内存占用是由单个步骤所需的最大占用定义的
# async/await
# Stream trait
# 实战篇
# 生产环境

# 数据处理
# 软件架构
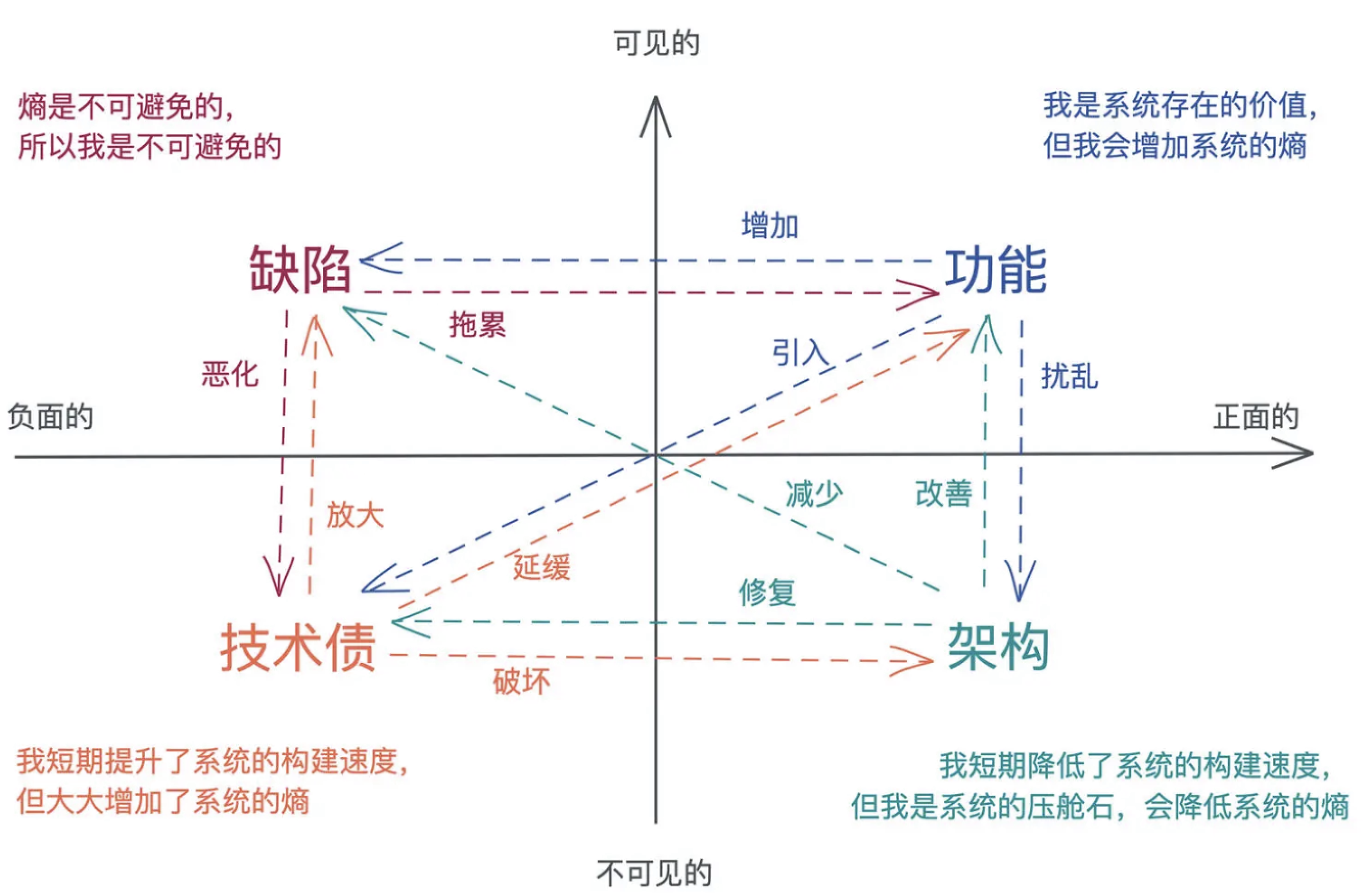
渐进式的架构设计,从 MVP 的需求中寻找架构的核心要素,构建一个原始但完整的结构(primitive whole),然后围绕着核心要素演进
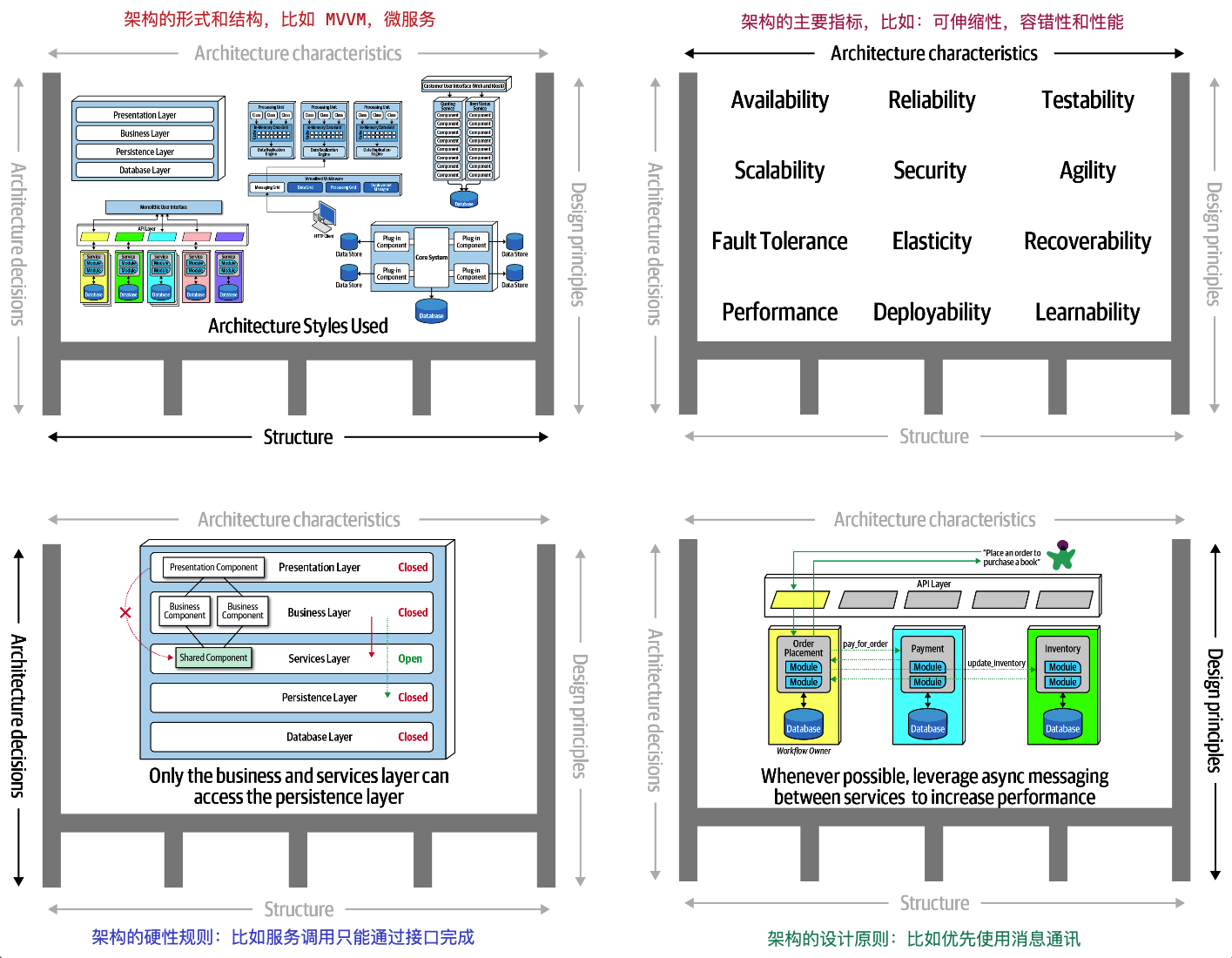
分层结构、流水线结构和插件结构
# 高级篇
# 宏
syn/quote